

在傳統的信息系統中,數據往往被靜態地存儲在數據庫或硬盤中,保護數據的方式也相對簡單——只需將其“鎖起來”即可。但隨着生成式人工智能(GenAI,Generative AI)的快速發展,數據開始在模型的訓練、部署、調用、生成等多個環節中持續“流動”,不再是一個靜態的資源,而成爲 AI 系統生命週期中活躍的參與者。
數據的流動性給其保護帶來了新的挑戰:我們不僅要防止數據泄露和濫用,還要確保在數據被使用的同時,依然保有“知情、可控、可溯源、可刪除”等基本權利。換句話說,在生成式人工智能時代,數據保護不再等同於一刀切的“封鎖”,而需要更加細緻、動態的治理方案。
正是基於這些觀察,來自浙江大學區塊鏈與數據安全全國重點實驗室和新加坡南洋理工大學等團隊的研究人員進行了一項聯合研究,旨在以通俗易懂的語言向廣大讀者闡述數據保護在生成式人工智能時代下的具體內涵與深遠影響。
該工作系統地梳理並回答了數據保護在人工智能時代下面臨的一系列關鍵問題:哪些數據要保護?應該採取怎樣的保護措施?可能會遇到哪些新挑戰?目前的相關法規和監管現狀如何?數據保護和數據安全存在怎樣的區別與聯繫?研究團隊進一步提出了一套分層次的數據治理框架,試圖在安全性、可用性與可監管性之間找到新的平衡。
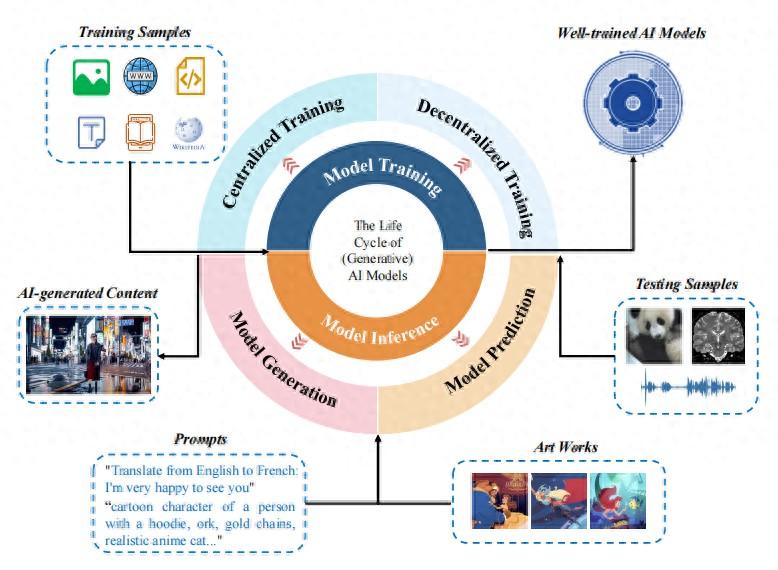
(來源:arXiv)
需要了解的是,傳統的數據保護理念是“以數據爲中心”,無論訓練還是保護都圍繞數據本身展開;而該研究提出,在 AI 時代,數據保護本質是“以模型爲中心”,這樣的數據是在與 AI 模型的開發、應用、交互、生產過程中創造價值。
研究人員以模型爲核心主線,重新梳理了其全生命週期中可能接觸的數據類型以及涉及的各個環節,包括訓練數據、訓練後的模型、系統提示詞、外掛知識庫、用戶輸入的數據與 AI 生成內容等。
不同於以往數據保護中“加密加水印”的簡單方法,他們提出了一種覆蓋四個關鍵層級的保護框架——數據不可用性、隱私保護、可追溯性和可刪除性。這一創新視角爲未來 AI 技術的健康、可持續發展及其治理體系建設指出了明確的方向。
該論文第一作者、曾任浙江大學區塊鏈與數據安全全國重點實驗室特聘研究員、現新加坡南洋理工大學研究員(Research Fellow)李一鳴博士對 DeepTech 表示:“我們的核心目標是闡明數據保護在 AI 時代的關鍵內涵與價值——這也與當前全球範圍內推動可信賴 AI 發展的主流訴求高度契合。”
目前,相關論文以《生成式人工智能時代下的數據保護再思考》(Rethinking Data Protection in the(Generative)Artificial Intelligence Era)爲題發佈在預印本網站 arXiv[1]。南洋理工大學研究員李一鳴博士是第一作者,通訊作者由李一鳴博士和浙江大學秦湛教授共同擔任。

圖丨相關論文(來源:arXiv)
該團隊構建了一套從 Level 1 到 Level 4 保護強度逐級遞減的保護框架——從“最嚴格”逐漸降到“最低限度”,每往下一級,其保護強度隨之遞減,而數據效用則隨之相應提升。
Level 1,數據不可用性(Non-usability):這是最高級別的數據保護,需確保特定數據無法用於模型訓練或推理。例如,在此前三星員工誤把源碼貼進 ChatGPT 的事件中,就可以通過“數據不可用性”進行前置性保護。
Level 2,隱私保護性(Privacy-preservation):在保護隱私信息前提下,數據可用於模型開發和應用,也就是數據“可用不可見”,相當於數據脫敏後再使用,降低了數據隱私泄露的風險。
該要求在以往的技術和相關法規中其實就已被提出過,李一鳴舉例說道:“例如差分隱私在訓練階段注入噪聲,聯邦學習將原始記錄留在本地只上傳梯度,同態加密則允許雲端直接對密文運算。”
Level 3,可追溯性(Traceability):這是最新的法規要求,允許數據可使用,但數據必須通過數字水印或區塊鏈等技術記錄數據來源和使用與修改歷史,並能夠在訓練或推理得到的模型和生成內容中得到校驗,也就是“用後留痕”。
Level 4,可刪除性(Deletability):這是最寬鬆的數據保護級別,允許數據完全用於訓練和推理,賦予用戶“被遺忘權”,允許其數據的影響從模型中徹底清除。
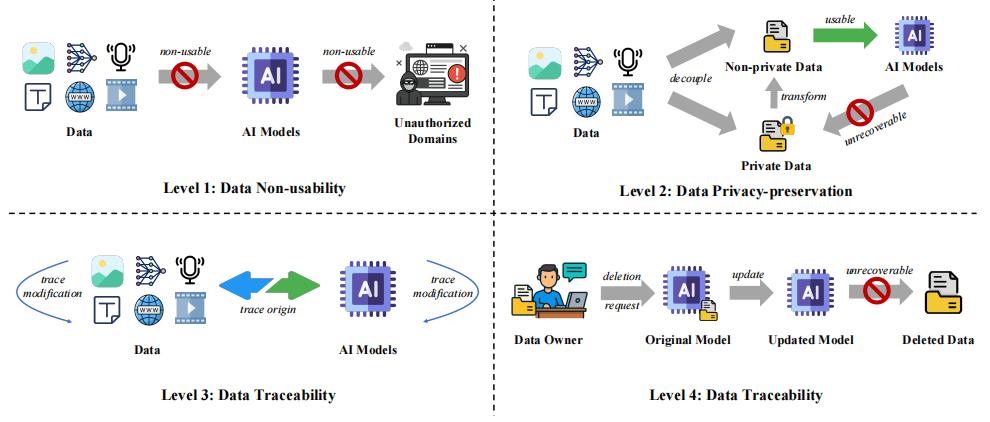
圖丨生成式 AI 時代數據保護的層級分類(來源:arXiv)
實際上,由於各國家和地區對數據保護的要求具有顯著差異,現有數據保護法規的覆蓋面可能存在缺口。例如,歐盟的《通用數據保護條例》和《人工智能法案》明確提到了“可刪除性”,美國加州的《加州消費者隱私法》強調“知情權”,中國的《個人信息保護法》和《生成式人工智能服務管理辦法》則更加聚焦規範水印與標識。
然而,這會導致跨國數據治理的難題:當前,大模型的訓練流程往往分散在全球。創業公司可能通過“地點切換”來規避法律層面的嚴格約束,例如在數據保護薄弱的國家採集訓練數據,然後去模型監管寬鬆的地區完成訓練和微調,再把服務部署到尚未規定刪除權的司法管轄區,以將合規成本降到最低。
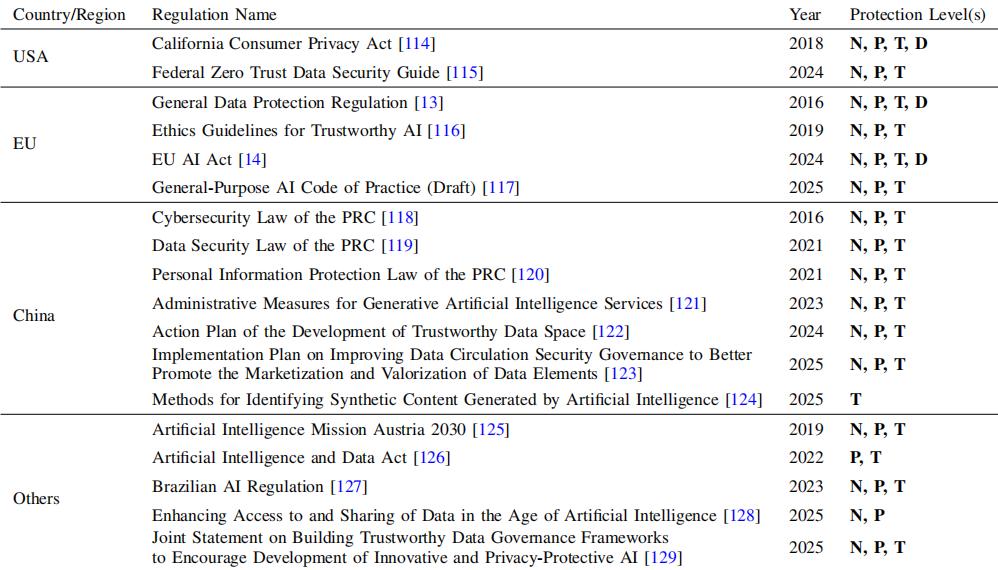
表丨生成式工智能時代數據保護的代表法規(來源:arXiv)
針對這一複雜局面,該研究提出了突破性的治理視角:當代數據保護的核心已從單純的“數據封鎖”轉變爲“價值的可控流動”。這種理念在具體應用場景中體現爲:醫療 AI 可學習病例特徵模式但不泄露患者隱私;法律 AI 能引用數據庫中的以往判例邏輯卻不可輸出數據庫中完整的判決書。
實現這種平衡需要多重技術支撐,例如,差分隱私保障訓練過程隱私,數字水印追蹤內容流向,聯邦學習促進多方數據協作。特別值得注意的是,這些技術方案同時服務於“數據保護”與“數據安全”雙重目標,反映出二者日益融合的趨勢:當模型能夠抵禦成員推理攻擊時,既保護了訓練數據隱私,也增強了模型自身的安全性。

圖丨李一鳴(來源:李一鳴)
李一鳴在清華大學計算機科學與技術專業獲得博士學位,曾任浙江大學區塊鏈與數據安全全國重點實驗室特聘研究員。目前,他在南洋理工大學擔任研究員(Research Fellow),研究方向爲可信人工智能,尤其是 AI 安全評測和 AI 版權保護。
在論文的討論部分,他與合作者還專門辨析了”數據保護“與”數據安全“的異同。原則上,二者關注點不同:前者聚焦模型及其所涉數據的隱私合規,後者強調模型本身及系統的穩健性。但在實踐中,二者深度交織——數據保護不足可能導致系統不安全,反之亦然;聯邦學習、差分隱私等技術已成爲跨領域的通用解決方案。
正如研究中所提醒的那樣,“數據保護不等同於數據安全”。該分層框架的價值在於把數據保護治理的顆粒度拆細,讓產業界不必在“全封閉”與“全開放”之間二選一,而是像“調音量”一樣,爲不同場景、不同法域找到風險與創新的最佳平衡點。“我們相信,完善的數據治理方案將爲更廣泛範圍的安全治理奠定堅實基礎。”李一鳴說。
參考資料:
1.https://arxiv.org/abs/2507.03034
運營/排版:何晨龍



