

從一鍵生成操作系統內核,到從零手搓一個 C 編譯器,編程智能體(Coding Agent)的能力邊界正在瘋狂擴張。
但一個更棘手的問題是:這些代碼,真的對嗎?當自動生成的代碼規模迅速膨脹,一個幽靈般的挑戰始終揮之不去:代碼能跑,但邏輯深處的 bug 多到令人頭皮發麻。
對於大語言模型(LLM)來說,寫出語法正確的“磚塊”輕而易舉,但距離用這些磚塊搭建一座安全穩固的“摩天大樓”仍有顯著的差距。因此,如何更好地保障大規模代碼的正確性,正成爲一個日益重要的問題。
近日,上海交通大學 IPADS 研究團隊打造了形式化方法智能體 FM-Agent,首次實現了面向大規模系統的全自動正確性推理。
在 Anthropic、NVIDIA 等用頂尖編程智能體生成的多個大規模系統(單個系統規模高達 14.3 萬行)中,FM-Agent 成功找到了 522 個隱藏 bug。值得關注的是,這些 bug 經過單元測試、差分測試、多智能體交叉審查等手段都未能發現。

圖丨相關論文(來源:arXiv)
相關論文以《FM-Agent:通過基於大語言模型的霍爾邏輯推理將形式化方法擴展至大規模系統軟件》(FM-Agent: Scaling Formal Methods to Large Systems via LLM-Based Hoare-Style Reasoning)爲題發表在預印本網站 arXiv[1]。
論文作者包括上海交通大學 IPADS 團隊的陳海波教授、王肇國教授和丁浩然博士。目前,研究團隊已推出 FM-Agent 源碼和網站[2,3],提供 FM-Agent 在線服務,用戶提供代碼壓縮包、API Key 和模型名稱後即可開始驗證。

圖丨從左至右分別是:王肇國、陳海波和丁浩然(來源:受訪者)
跳出“將錯就錯”:AI 開始從需求驗證代碼
那麼,FM-Agent 是如何將形式化方法用於大規模系統的?要理解這個問題,我們得先回溯到圖靈獎得主託尼·霍爾(Tony Hoare)早在 20 世紀 60 年代爲代碼驗證指明的方向——組合式推理(Compositional Reasoning)。
組合式推理的基本思想非常優雅:爲了驗證複雜系統的正確性,首先把它拆解成一個個獨立的小函數。然後,給每個函數寫一份精確的形式化規約(Formal Specification),即一份用數學語言寫成的“說明書”,說明執行函數前程序狀態需要滿足什麼條件(前置條件),執行後函數保證輸出什麼樣的結果(後置條件)。最後,只要分別證明每個函數的實現(Implementation)和規約一致,就能直接推理出整個系統滿足正確性。
儘管組合式推理的願景很美好,但一個關鍵的現實問題是,形式化規約需要靠人類專家用極其嚴謹的數學公式手寫,人力成本高昂。在 LLM 生成代碼的時代,迅速放大了這個痛點。
陳海波對 DeepTech 表示:“當編程智能體可以生成 10 萬行以上代碼時,開發者對內部的函數行爲本就一知半解,爲成百上千個函數編寫形式化規約更不可行。因此,儘管相關工作在自動生成證明方面取得了長足的進步,但是從本質上來看形式化方法仍然是‘屠龍之術’,難以推廣至大規模系統軟件。”
此前,也有研究工作嘗試用 LLM 自動生成規約,但卻掉入了“將錯就錯”的陷阱:通過分析函數本身的實現來反推規約。但如果函數實現本身就有 bug,那麼反推出來的規約也容易被誤導。
這就像是鸚鵡學舌(複述函數的工作流程),把 bug 當成正確行爲寫進去,會直接導致後續的驗證無法發現 bug。關鍵在於,函數本身可能不可靠,但調用它的上下文往往更接近真實需求。
爲了解決這一問題,FM-Agent 提出了新方法:既然函數自己的實現可能會騙人,那就去問函數的“上級”——那些調用它的函數。下圖展示了調用者驅動的規約自動生成方法,基本思想是結合函數實現、調用者期望和領域背景知識,讓 LLM 爲函數生成規約。
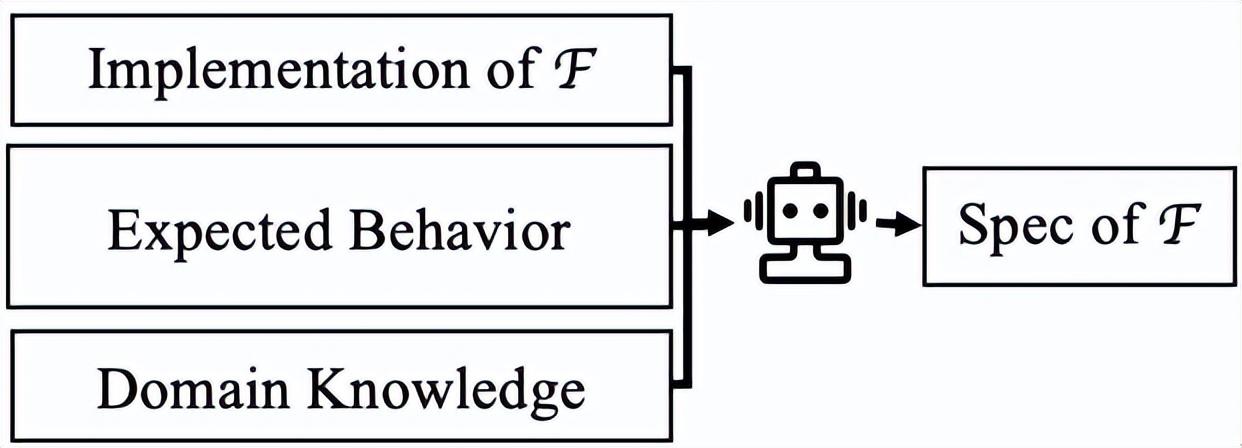
圖丨調用者驅動的函數 F 規約自動生成(來源:arXiv)
王肇國對 DeepTech 解釋:這就像是甲方(調用方)交給乙方(被調用函數)一個任務,要求輸入合格的材料(前置條件),必須交付合格的產品(後置條件)。哪怕乙方在內部施工時偷工減料、走了彎路(bug),甲方對這份工作的原始要求依然是清晰且正確的。
從本質來看,FM-Agent 做了兩件事:一是重新定義規約的來源,二是用 LLM 完成推理過程。FM-Agent 就是那個拿着甲方原始合同,去驗收乙方成果的質檢員。


(來源:arXiv)
如下圖所示,FM-Agent 提出了一種創新的自上而下規約生成範式:從用戶對系統整體正確行爲的期望出發,逐步推導出每個函數應滿足的規約。這樣做可以避免被具體實現誤導,生成的規約描述的是函數“應該做什麼”,而不是“怎麼做”。
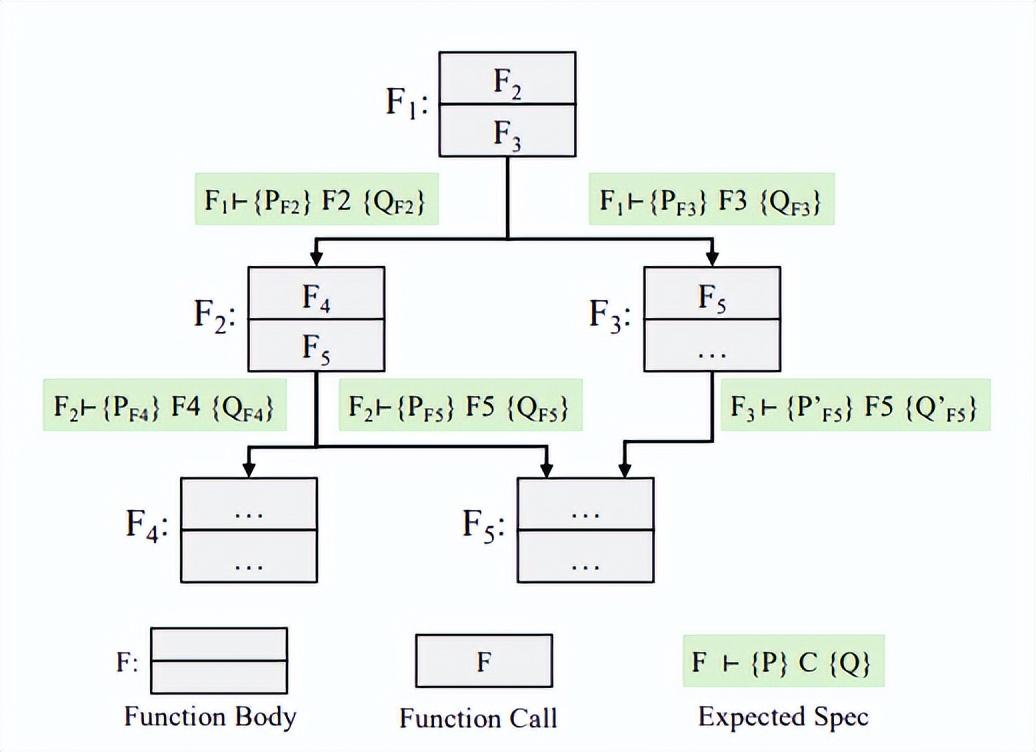
圖丨自上而下的規約生成新範式(來源:arXiv)
在推理過程的可靠性方面,研究團隊並不是直接讓 LLM 判斷代碼是否正確,而是將思維鏈(Chain of Thought)與霍爾邏輯的推理規則相結合,引導 LLM 逐步推導每個代碼塊執行後程序狀態所滿足的性質,最終檢查程序狀態是否符合“說明書”的要求。
此外,對於可能存在 bug 的函數,LLM 會基於推理過程嘗試生成測試用例來觸發 bug,只有成功觸發的 bug 纔會被最終報告給開發者,進一步提升了 bug 上報的準確性。
那麼,如何在絕對嚴謹與工程可用之間取得平衡呢?FM-Agent 的基本思路是:先分析 LLM 擅長什麼,然後將其與傳統形式化驗證流程進行對照,判斷哪些步驟可以適當放寬對“絕對嚴謹”的要求,從而換取“工程可用”。
這一平衡的關鍵在於利用 LLM 的兩項能力:一是在提供函數調用上下文的前提下,能夠理解每個函數的意圖;二是在處理較短程序時,能根據輸入準確推導輸出。它們分別支撐了 FM-Agent 自動生成規約和自動推理程序正確性的能力。
在層層測試之後,AI 依然挖出最隱蔽的 Bug
儘管已有規約,但新的問題接踵而至。“用戶通常使用自然語言描述系統設計,FM-Agent 生成的規約也是自然語言,而傳統形式化驗證器只支持基於數學公式的推理,二者存在巨大的語義鴻溝。”丁浩然表示。
針對這一問題,研究團隊發現了一個關鍵事實:LLM 對於小段代碼的執行結果預測極其精準。結合 LLM 對代碼和自然語言的理解能力,FM-Agent 大膽泛化了霍爾邏輯中的推理規則,讓 LLM 直接基於自然語言規約對函數的正確性進行邏輯推理。

圖丨基於自然語言的代碼正確性推理示例(來源:arXiv)
如上圖所示,FM-Agent 逐段推理代碼執行後的程序狀態描述(註釋部分),即後置條件,一直推理到函數返回,檢查最終的程序狀態描述是否違背了規約裏對最終程序狀態的要求。
這種方法結合了霍爾邏輯的推理規則和 LLM 強大的語義理解能力,實現了對大規模代碼的“找茬”。

表丨智能體自動生成的大規模系統(來源:arXiv)
爲了驗證 FM-Agent 的實戰能力,研究團隊對四款由 Claude Opus、GPT Codex 等頂尖編程智能體生成的大規模系統進行了正確性推理。
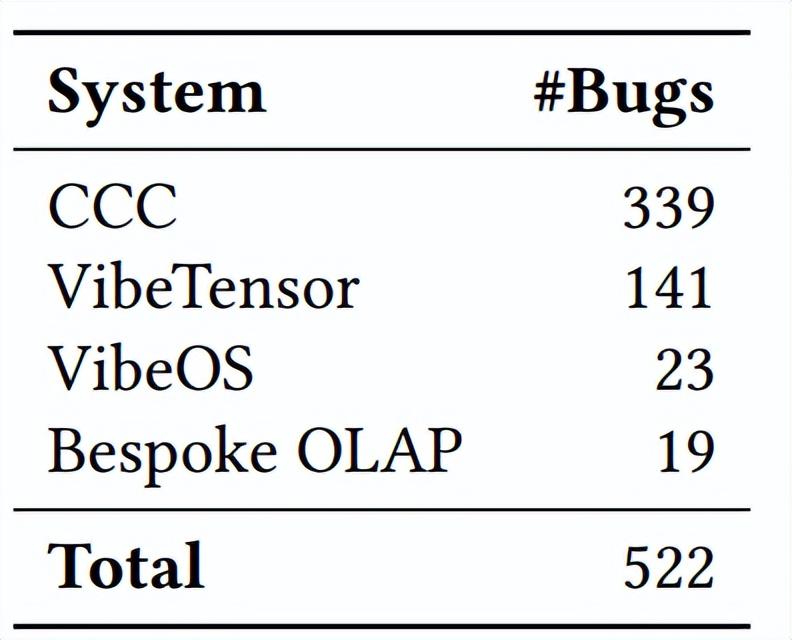
表丨FM-Agent 在大規模軟件中找到的 bug 數量(來源:arXiv)
這些系統此前已經過開發者的單元測試、集成測試、差分測試甚至多智能體交叉代碼審查等。然而,FM-Agent 在這些“層層設防”的堅固堡壘中,依然挖出了 522 個新 bug。
除了導致系統崩潰、結果錯誤這種顯性問題,FM-Agent 還發現一些更深層的邏輯隱患。例如,編譯器 CCC 中發現的一些 bug 會導致代碼雖然可以正常編譯,但是代碼的執行結果卻是錯的。這種“無聲無息”的 bug 不會導致系統崩潰或任何明顯異常,但危害極大且難以被察覺。

(來源:arXiv)
當前編程智能體之所以會引入這種“細思極恐”型 bug,很可能與其訓練數據中包含了類似的錯誤代碼有關。陳海波指出,未來若想進一步提升編程智能體生成代碼的可靠性,一個關鍵方向是對訓練數據進行更嚴格的篩選,儘可能使用正確無誤的代碼來訓練智能體,這或許也是未來 FM-Agent 的應用場景之一。
此外,FM-Agent 還會基於推理過程提供的信息,自動生成能觸發 bug 的測試用例。例如對於編譯器 CCC,FM-Agent 會生成 C 程序作爲測試用例,並將 CCC 的編譯結果與參考實現(例如 GCC)比較。“這種可復現的證據鏈,對於輔助理解和修復 bug 非常重要。”王肇國表示。
在 LLM 時代,如何讓形式化方法的腳步快速跟上編程智能體的發展速度變得越發重要。FM-Agent 並非追求傳統形式化驗證那種絕對完美的數學證明,而是利用 LLM 的推理能力在絕對嚴謹與工程可用之間找到一個絕佳平衡點。
隨着 FM-Agent 這類技術成熟,未來的軟件工程範式可能會發生根本性變化。人類開發者的核心工作流有可能會變爲:首先由人用自然語言對整個系統編寫設計文檔,之後由 AI 根據設計文檔生成代碼,然後 AI 對代碼找 bug 並自動修復。
人將從“編寫-調試-修復”的循環中解放出來,轉移到需求分析與系統設計上,設計文檔的質量直接決定了 AI 生成代碼的準確性和可維護性。
新的軟件開發流程可能給軟件工程的教育和人才培養領域帶來顛覆性的改變。當前的培養課程重點是編程語言、數據結構、算法實現、調試技巧等,在“AI 生成+驗證”的範式下,這些傳統能力大部分可能不再是核心的培養目標。因此,抽象建模能力、領域知識深度、系統思維、思辨能力等將變得越來越重要。
研究團隊認爲,隨着形式化方法的不斷進步,形式化驗證的下一個“聖盃”是貫穿軟硬件全棧的端到端保證。這涉及多個大規模系統的正確性保障,而操作系統內核正是全棧中的關鍵一環。完全自動化的操作系統內核驗證,可以視作通往軟硬件全棧端到端保證的重要里程碑。
在 20 世紀 60 年代,託尼·霍爾提出了今天形式化驗證的重要基石——霍爾邏輯,然而直到他今年逝世前,形式化驗證仍然囿於人力成本,難以擴展至大規模軟件中。
FM-Agent 提出了首個面向大規模系統的全自動組合式推理框架,回應了這份夙願,也爲形式化方法卸下“屠龍術”的沉重鎧甲,大步走向千行百業開闢了一條全新的道路。當 AI 負責寫代碼,另一個 AI 負責證明它是對的,軟件工程的核心問題,正在被重新定義。
參考資料:
1.相關論文:
https://arxiv.org/abs/2604.11556
2.FM-Agent源碼:
https://github.com/haoran-ding/FM-Agent
3.FM-Agent網站:https://fm-agent.ai/
排版:劉雅坤



