

如果把身體看作一座城市,病毒或癌細胞便是潛在的入侵者,但是否發起反應、反應有多強,取決於免疫系統能否正確識別、有效傳達“入侵警報”。而 CD4+ T 細胞免疫過程就像是一整套城市安保系統,涵蓋了從偵察、信息傳遞,到動員反應的層層環節。
最近,澳大利亞莫納什大學宋江寧教授和南京理工大學於東軍教授的聯合團隊,開發了一種名爲 ImmuScope 的弱監督深度學習框架,集成了精確的主要組織相容性複合體 II 類(MHC-II,Major Histocompatibility Complex-II)抗原呈遞、CD4+ T 細胞表位和免疫原性預測。
其作用相當於高智能的“安保指揮中心”,通過分析成千上萬種“可疑信號”(抗原肽段),判斷它們是否能被展示給 CD4+ T 細胞、是否能激發真正的免疫反應。不僅告訴系統“這裏有問題”,更進一步預測“這個問題是否嚴重、是否值得啓動響應”。
也就是說,ImmuScope 不是在前線作戰,而是在幕後決策,它像一個會學習、會判斷的免疫情報分析系統,幫助人們在面對癌症或病毒變異時,更快、更準地找出哪些目標應該被優先“通緝”(可能的突變),有望爲新型疫苗設計、腫瘤新抗原篩選以及自身免疫疾病相關表位的識別等實際應用場景提供輔助。
在疫苗開發方面,它可以更高效地篩選出可能激發 CD4+ T 細胞反應的抗原,提高早期設計的精準性。在免疫治療中,有望輔助識別個體化的治療靶點,優化治療策略。在黑色素瘤的新抗原研究中,ImmuScope 也展現出應用潛力。它能幫助解突變如何影響抗原呈遞和免疫識別,爲未來腫瘤免疫治療中的個體化靶點發現提供啓示。
宋江寧對 DeepTech 表示:“更重要的是,ImmuScope 能夠識別在抗原-抗體相互作用中有貢獻的接觸殘基,並確定哪些相互作用重要。同時,還能提供決定序列模體的殘基位置,這對於指導新抗原設計具有重要價值。”

圖丨宋江寧(左)與申龍晨(來源:宋江寧)
近日,相關論文以《自迭代多示例學習算法實現 CD4+ T 細胞免疫原性表位預測》(Self-iterative multiple-instance learning enables the prediction of CD4+ T cell immunogenic epitopes)爲題發表在 Nature Machine Intelligence 上[1]。南京理工大學博士生申龍晨是第一作者,莫納什大學宋江寧教授和南京理工大學於東軍教授擔任共同通訊作者。

圖丨相關論文(來源:Nature Machine Intelligence)

不僅能“看到”抗原呈遞,還能“理解” T 細胞響應強度
傳統 CD4+ T 細胞表位預測方法主要依賴單等位基因(SA,single-allelic)數據。這類數據提供了非常清晰的一對一信息,即某個肽段確切地和某個 MHC-II 分子結合。它就像是在做一項“精密配對”的工作——每條信息都很可靠,但問題在於數據量不夠,尤其對於 HLA-DQ 和 HLA-DP 這類等位基因覆蓋嚴重不足。
然而,追求這種高質量數據的代價往往是犧牲廣度。實際上,現在已經積累了大量的多等位基因(MA,multi-allelic)數據,但這些數據是弱標記的。例如,你可能知道某個肽段與某些 MHC-II 分子發生了結合,但不知道更具體的信息。
過去很多模型沒辦法處理這種模糊的信息,所以乾脆忽略 MA 數據。該團隊意識到,如果不能利用這類數據,就很難突破預測模型的廣度限制。因此,他們的研究目標是解決核心問題:如何從模糊中提煉出可靠的信息,讓模型學會從“混合樣本”中識別出準確的肽-MHC 配對關係。
宋江寧團隊的主要研究方向是利用異構數據建模、先進的機器學習和分析技術來應對感染與免疫、癌症生物學和藥物信息學領域的關鍵挑戰(DeepTech 此前報道:科學家提出深度學習新模型,精準預測T細胞受體與抗原相互作用)。
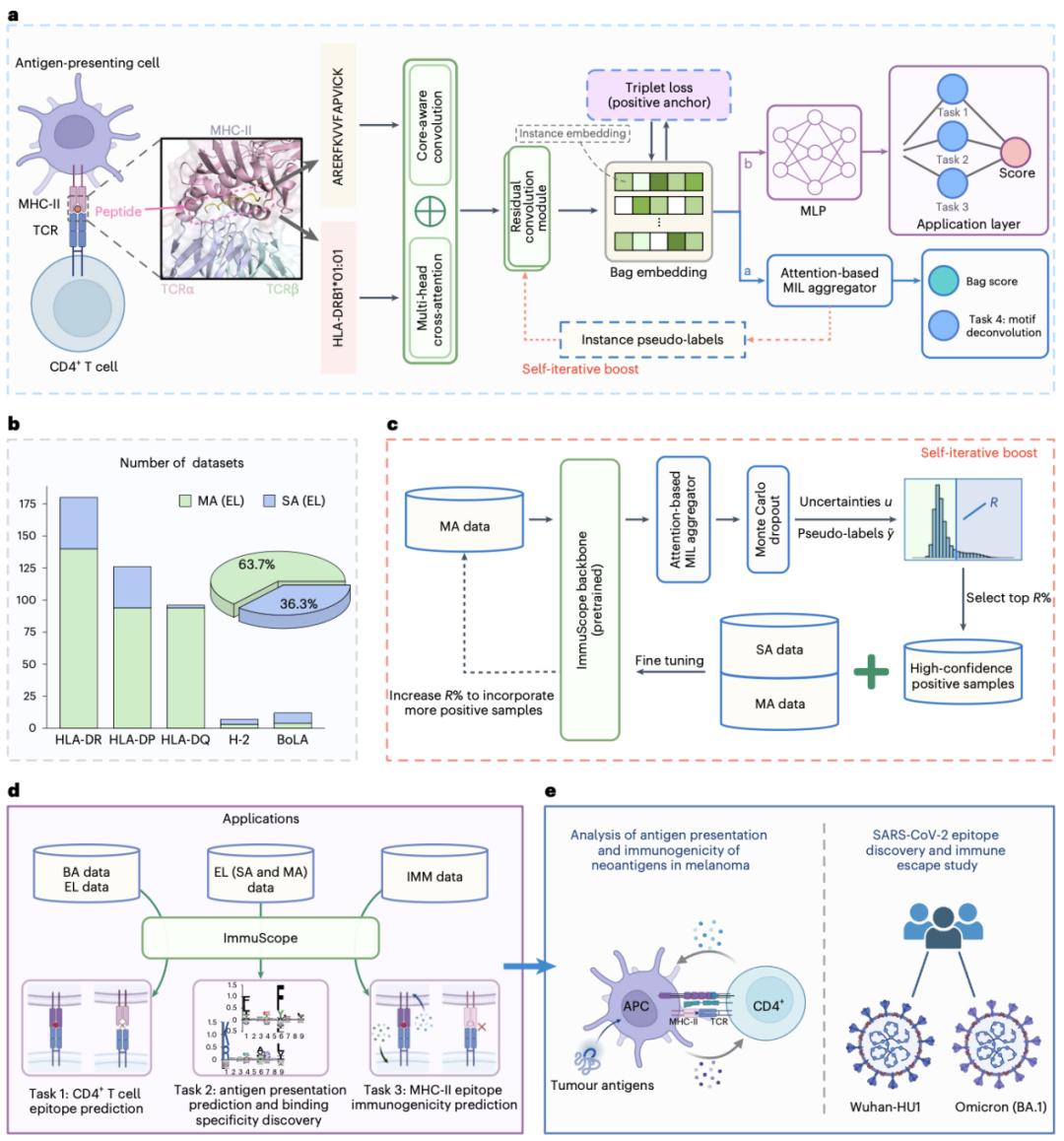
圖丨ImmuScope 改進了 CD4+ T 細胞表位預測(來源:Nature Machine Intelligence)
本次研究提出的 ImmuScope 是通過自我迭代的多示例學習方法,結合高質量註釋篩選,把原本模糊的多等位基因數據“逐層剝離”。
這就像是有多個上了鎖的盒子和一把鑰匙,但不知道鑰匙對應能打開哪個盒子,只知道“至少有一個盒子被打開了”。ImmuScope 通過反覆推理與篩選,最終找出鑰匙真正對應的盒子,從而有效擴展了等位基因的覆蓋範圍,並顯著提升了預測的準確性與魯棒性。
從抗原與 MHC-II 分子的結合開始,到被 T 細胞識別,最終決定是否觸發免疫反應,這一系列過程實際上構成了一個層層遞進的級聯反應,每個環節都是一道關鍵的篩選關卡,缺一不可。
而 ImmuScope 把這個免疫“閉環”建模成一個可學習的系統,不僅訓練模型預測抗原是否能被 MHC-II 分子呈遞,還進一步評估它的結合特異性、是否會被 CD4+ T 細胞識別,甚至它最終是否具備免疫原性。
更進一步,該團隊並不僅僅停留在抗原呈遞這一環節,而是試圖構建一個覆蓋整個 CD4+ T 細胞免疫反應流程的統一框架,從 MHC 結合到 T 細胞識別、再到免疫原性預測。“我們相信,只有真正把這些步驟串聯起來,才能更好地理解 T 細胞免疫機制,並推動它在癌症、病毒感染等疾病中的實際應用。”宋江寧說。
從技術層面來看,該研究整合了來自單等位基因和多等位基因的大規模數據(包含 142 個等位基因的超 60 萬個配體),用多示例學習的方法充分吸收弱標註信息。同時,引入了正錨三元組損失(positive-anchor triplet loss)來提高模型辨別能力,能更精準地識別正負樣本的特徵差異。
在結構上,ImmuScope 的多個子模塊分別對應抗原呈遞預測、特異性分析、表位預測和免疫原性評估,並通過統一的特徵表示聯通。此外,研究人員還在多個疾病背景下驗證了它的適用性,包括黑色素瘤新抗原識別和新冠病毒變異的免疫逃逸分析。
簡單來理解,ImmuScope 就像是一個覆蓋全流程的免疫建模引擎,不僅能“看到”抗原呈遞,還能“理解” T 細胞是否會響應、響應多強,爲疫苗設計和個體化免疫治療提供了一站式解決方案。

首次把 CD4+ T 細胞免疫流程整合到統一的 AI 框架
實際上,很多現有工具只聚焦於 CD4+ T 細胞免疫過程中的某一個環節,比如只預測抗原是否能與 MHC-II 結合,或單獨評估表位的免疫原性。儘管這些方法各有優勢,但很難全面把握整個免疫反應的多步驟啓動過程。
ImmuScope 的獨特之處在於,首次把整個 CD4+ T 細胞免疫流程整合到統一的 AI 框架中。它能幫助科研人員解決一系列下游問題,包括:預測抗原呈遞、識別 MHC-II 結合特異性、預測 T 細胞是否能識別表位,以及判斷這個表位是否可能激發免疫反應(即評估免疫原性)。
另一個關鍵優勢是利用了弱標註的多等位基因數據,這類數據雖然複雜,但覆蓋範圍廣,能極大擴展模型在真實人羣中不同 MHC-II 亞型上的適用性。ImmuScope 通過自迭代學習的方式有效“淨化”這些數據,從中提取出高置信樣本,這在以前的模型中很少見。
這個過程就像“沙裏淘金”:先用現有經驗找出最亮眼的“金粒”,再把這些樣本反過來繼續訓練模型,提升它在複雜數據下的判斷力。通過不斷迭代這個過程,讓模型越來越擅長從模糊、弱標註的數據中提取出高質量信息,從而大幅提升了預測的廣度和準確性。
此外,他們還設計了特定的損失函數和注意力機制,讓模型不僅準確,還具備較強的可解釋性和泛化能力。在多個任務和數據集上對比測試,ImmuScope 在預測準確性和穩定性上都超過了現有的主流方法。
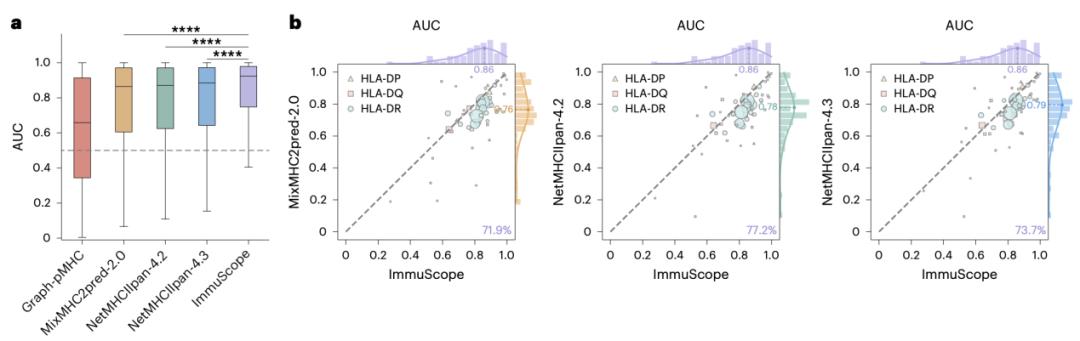
圖丨CD4+ T 細胞表位預測性能的基準測試(來源:Nature Machine Intelligence)
除了 CD4+ T 細胞表位測試基準的平均 AUC(Area Under the Curve)達到 0.825,領先於 NetMHCIIpan-4.3 和 MixMHC2pred-2.0 之外,最具代表性的優勢體現在兩個方面:
一是對不同 HLA 等位基因的適應性更強。分析結果表明,ImmuScope 在絕大多數等位基因上都取得了更高的 AUC,尤其在 HLA-DQ 和 HLA-DP 這些過去數據較少、預測困難的等位基因上,依然保持了較強的穩定性。
二是對不同肽段長度的預測也更穩健。不論是短肽還是長肽,ImmuScope 基本都保持了領先表現,顯示出模型的泛化能力非常強。
這些性能提升關鍵在於兩個模塊:首先是自迭代的多示例學習機制,它可以有效利用弱標註的多等位基因數據,提取出高置信樣本,顯著擴大了訓練數據的廣度和質量;其次是引入的正錨三元組損失函數,提升了模型在正負樣本之間的判別力,特別有助於發現精細的 MHC 結合特徵。
整體來說,ImmuScope 並不是依賴某一個“神奇算法”,而是通過多個創新模塊協同工作,形成了一個既精準又穩健的免疫預測框架。

有望在疫苗設計和個體化治療發揮關鍵作用
據介紹,ImmuScope 的研究過程是一條不斷迂迴探索的路徑。在研究伊始階段,該團隊在嘗試將多等位基因數據有效引入模型訓練的過程中,模型表現一直不太穩定。儘管經過反覆調整方案,效果卻始終不理想,研究人員一度感到有些困惑。
後來他們逐步引入了自迭代僞標籤篩選機制,並結合注意力模塊優化樣本選擇策略。那一次,模型在驗證數據上的表現終於有了明顯提升。雖然只是一個階段性的進展,但給團隊帶來很大的鼓勵,也確認了該方向的可行性。
還有一個讓團隊印象深刻的瞬間,是把模型應用到黑色素瘤新抗原和 SARS-CoV-2 變異表位的預測中。前者驗證了模型在腫瘤免疫中的潛力,而在 SARS-CoV-2 的應用中,ImmuScope 能夠識別出變異對免疫識別的影響,有效捕捉了病毒免疫逃逸的信號。
宋江寧表示:“這讓我意識到,ImmuScope 不僅具備理論上的優勢,也展現出了一定的應用潛力,未來有望在疫苗設計和個體化治療中發揮作用。”
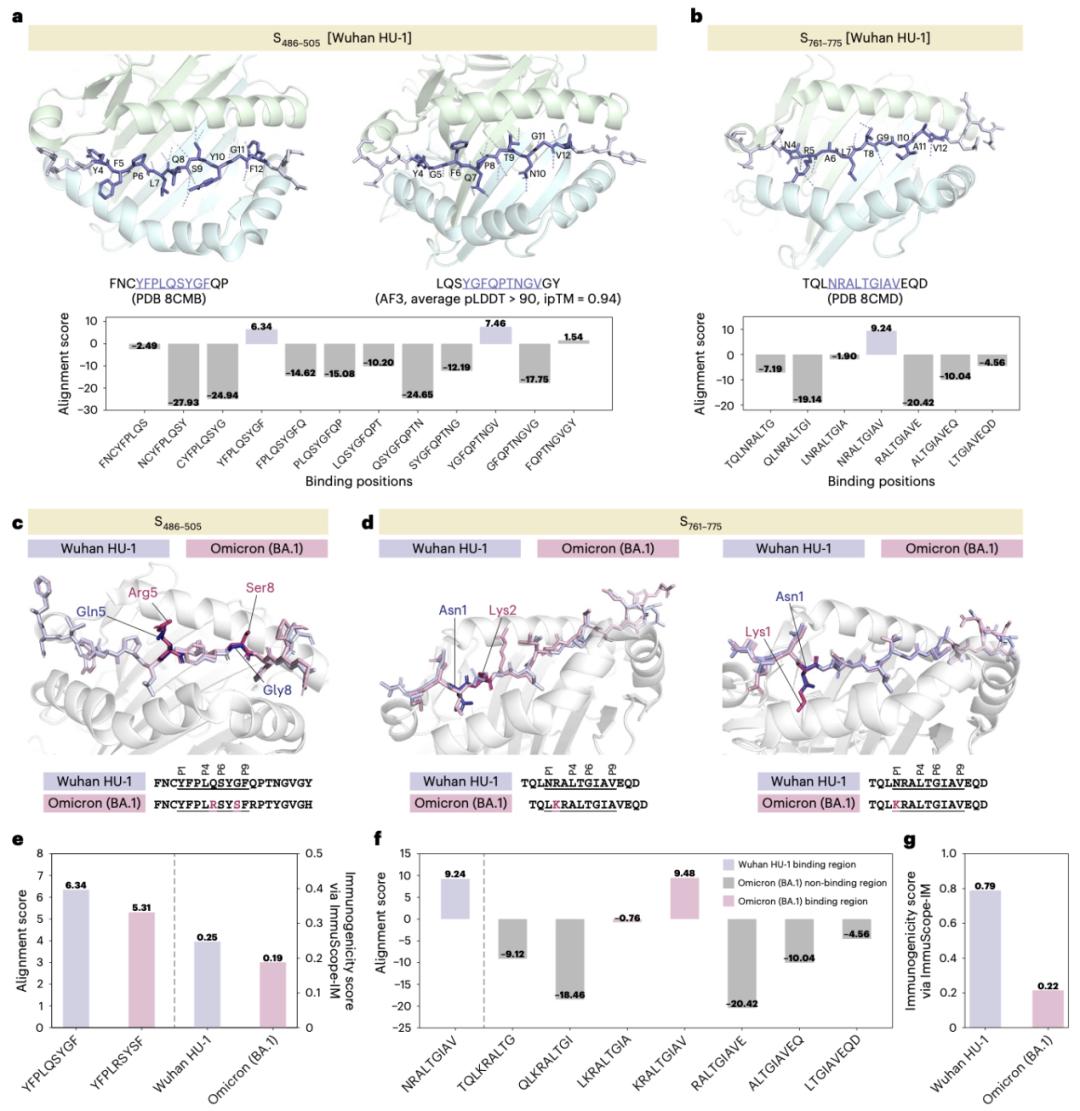
圖丨ImmuScope 在 SARS-CoV-2 刺突蛋白表位中預測的結合位置(來源:Nature Machine Intelligence)
據介紹,由於澳大利亞盛行咖啡文化,宋江寧與團隊成員經常在咖啡館進行比較輕鬆的討論。大家會點上一杯咖啡,打開筆記本電腦,一起交流科研想法。“一路走來,有過技術卡點,也有靈光一現的時刻,但最讓我難忘的,是團隊一起頭腦風暴、不斷試錯、不斷突破的過程。這也是科研中最有價值、最有成就感的部分。”他回憶道。
需要了解的是,ImmuScope 當前處於基礎研究階段,距離真正應用到臨牀還有一段距離,仍有一些關鍵問題需要逐步解決。比如,對免疫反應的理解、模型的解釋性和數據的全面性等方面,並需要更多臨牀和實驗研究來進一步驗證。
目前,ImmuScope 的相關代碼已經開源。在接下來的研究階段,團隊將繼續打磨模型的整體能力,同時也希望結合更多真實場景的數據,拓展它在疾病研究和個體化治療中的應用潛力,例如通過開發新的 AI 框架來解決非常見的免疫細胞類型相關的問題。
此外,除了使用現有的數據或基於建模後的預測數據之外,他們也在考慮整合多模態數據、跨模態數據,甚至病理圖像數據、腫瘤微環境數據以及空間多組學數據,以推進該框架進一步演化和發展。
“當然,這需要一個循序漸進的過程,我們會持續在這條路上探索和推進,未來也期待可以與合作伙伴爲疫苗設計和精準免疫治療提供更紮實的工具支持。”宋江寧說道。
參考資料:
1.Shen, LC., Zhang, Y., Wang, Z. et al. Self-iterative multiple-instance learning enables the prediction of CD4+ T cell immunogenic epitopes. Nature Machine Intelligence (2025). https://doi.org/10.1038/s42256-025-01073-z
運營/排版:劉雅坤、何晨龍



