

過去兩年多,投機解碼(Speculative Decoding, SD)幾乎成了業界加速 LLM 推理的標準手法。它的原理並不複雜:讓一個參數量更小、跑得更快的“草稿模型”(draft model)先猜測目標大模型接下來要生成的若干 token,再由大模型在一次前向傳播中並行驗證這批猜測。
猜對的直接採納,猜錯的丟棄後重新來過。這個由 Google Research 的 Yaniv Leviathan 等人在 2022 年底提出的方法,已經被 vLLM、SGLang、TensorRT-LLM 等主流推理引擎悉數收編,Google 自己也在今年 2 月的官方博客中專門回顧了這一技術的發展脈絡。
然而投機解碼有一個結構性瓶頸始終沒有被真正突破:草稿模型的“猜”和大模型的“驗”依然是串行的。每一輪驗證結束之後,草稿模型才能拿到結果,才能開始下一輪猜測。驗證器等草稿、草稿等驗證器,整個流程裏總有一方在閒着。
2026 年 3 月 3 日,來自斯坦福大學的 Tanishq Kumar、普林斯頓大學 Tri Dao(FlashAttention 核心作者之一),以及 Together AI 的 Avner May,在 arXiv 上貼出了一篇名字很有趣的論文《投機的投機解碼》(Speculative Speculative Decoding)。他們的核心問題只有一個:能不能把草稿和驗證之間最後這層串行依賴也給幹掉?

圖丨相關論文(來源:arXiv)
答案是可以,而且他們給出了一個完整的工程化方案,叫做 Saguaro(仙人掌柱,亞利桑那州那種巨型仙人掌的名字)。
在 Llama-3.1-70B 上用四張 H100 做推理,batch size 爲 1、貪心解碼的條件下,Saguaro 相比標準自迴歸解碼最高加速約 5 倍,相比已經優化過的投機解碼還能再快接近 2 倍。且這些數據橫跨了 HumanEval(代碼)、GSM8k(數學)、Alpaca(指令跟隨)和 UltraFeedback(對話)四個數據集的平均值,而不是隻選取某一表現最突出的個別場景。
在傳統的投機解碼中,草稿模型必須等驗證結果回來,才知道大模型接受了多少個 token、在哪個位置拒絕並採樣了所謂的“獎勵 token”(bonus token)。這個獎勵 token 是從殘差分佈(residual distribution)中抽取的,它的值直接決定下一輪猜測的起點。
SSD 的做法是:不等了。在大模型驗證當前這一輪猜測的同時,草稿模型就開始預測驗證結果可能是什麼樣的,有多少 token 會被接受?獎勵 token 最可能是哪幾個?
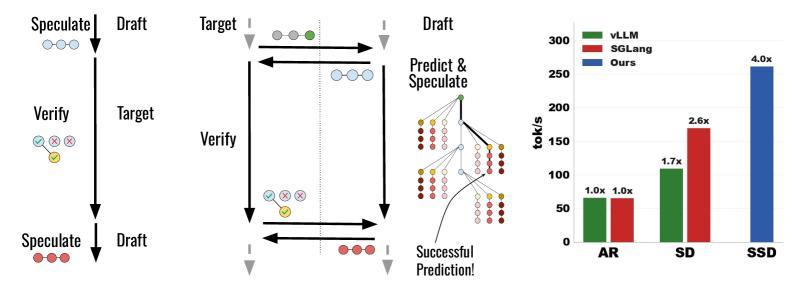
(來源:arXiv)
然後針對每一種可能的結果,預先準備好對應的下一輪猜測,存進一個叫“投機緩存”(speculation cache)的數據結構中。等驗證結果真正傳回來時,如果正好命中了緩存中的某個結果,草稿模型立刻返回預備好的 token 序列,完全跳過草稿階段的延遲。
如果沒命中,則退回到一個後備策略,相當於降級成普通的投機解碼。關鍵在於:命中緩存這件事不是偶爾發生的。論文報告的緩存命中率在貪心解碼下超過 90%,在溫度爲 0.7 的隨機採樣場景下也能維持在 70% 以上。
這套思路讓人聯想到 CPU 領域的投機執行(speculative execution)。處理器遇到條件分支時,不等判斷結果出來,先把兩條路徑都預執行一遍,猜對了就賺到了,猜錯了就回滾。作者在論文中也明確承認了這個類比。
區別在於,CPU 投機執行面對的分支通常只有兩三條路徑,而 LLM 驗證結果的空間是天文數字級別的(K+1)×V,K 是猜測長度,V 是詞表大小,對 Llama 系列而言 V 超過 12 萬。所以不可能爲所有結果都準備好緩存,必須在有限預算下選擇最有可能命中的那些。
Saguaro 針對這個問題提出了三層優化。第一層是緩存構建策略。論文證明了一個數學結論:在給定緩存總預算 B 的約束下,最優的“扇出”分配(即爲驗證序列中每個位置準備多少個候選獎勵 token)應該服從一個上封頂的幾何級數。
越靠後的位置(即更多 token 被接受的情況),被接受的概率本身就越低,分配的猜測預算也應該越少。這很符合直覺,但給出嚴格的最優解仍然需要一整套拉格朗日乘子法的推導。
實驗表明,相比均勻分配扇出,幾何扇出策略在高溫採樣時優勢尤其明顯,因爲高溫下驗證結果的不確定性更大,“把錢花在刀刃上”就更重要。
第二層是一個全新的採樣方案,作者稱之爲 Saguaro 採樣。在標準投機解碼中,當草稿 token 被拒絕時,獎勵 token 從殘差分佈中採樣,而殘差分佈的形式是 max(p_target - p_draft, 0) 的歸一化。這意味着殘差分佈重度依賴草稿分佈的形狀。
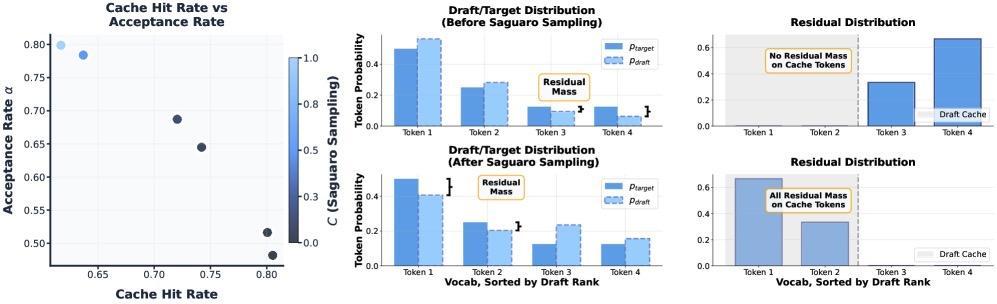
圖丨Saguaro 採樣(來源:arXiv)
Saguaro 採樣的策略是故意在草稿採樣階段壓低那些最可能成爲緩存候選的 token 的概率(乘以一個小於 1 的係數 C),這樣做會讓殘差分佈中的概率質量向這些候選 token 集中,從而提高獎勵 token 恰好落在緩存裏的概率。代價是草稿分佈偏離了目標分佈,接受率會下降。
但論文通過理論構造證明,存在一些目標/草稿分佈的組合,使得這種刻意偏移帶來的緩存命中率提升足以補償接受率的下降,在端到端速度上反而更快。超參數 C 提供了在兩者之間連續調節的旋鈕。
第三層關於緩存未命中時的後備策略。這一點隨 batch size 增大變得越來越關鍵,因爲 batch 中只要有一個序列沒命中緩存,整個 batch 就得等後備草稿完成。論文給出的策略是:在小 batch size 下,後備模型就用主草稿模型做即時投機(just-in-time speculation);當 batch size 超過某個臨界值 b* 時,切換到一個極低延遲的後備方案,比如返回隨機 token 甚至基於 n-gram 的非神經網絡投機器。
論文推導了 b* 的解析表達式,並用實驗驗證了這個切換點的位置與理論預測一致。
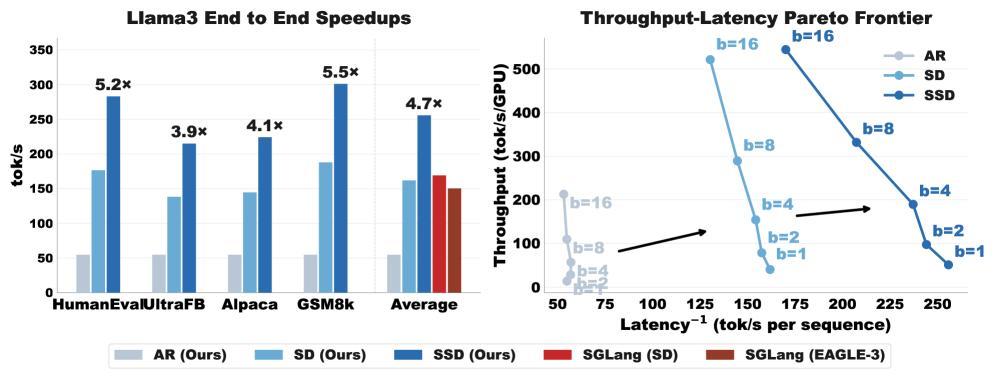
(來源:arXiv)
值得注意的是整個方法的一個前提:SSD 要求草稿模型運行在獨立於目標模型的硬件上。論文的實驗設置中,目標模型用四張 H100 做張量並行(tensor parallelism),草稿模型單獨佔一張 H100。
兩者之間通過 NCCL 通信,每輪交換的數據量很小,目標模型只需傳回接受了幾個 token 和獎勵 token 是什麼,草稿模型傳回預備好的 token 序列和 logits。這意味着 SSD 總共用了 5 張 GPU 而非投機解碼的 4 張。
但論文中關於吞吐 - 延遲帕累託前沿(Pareto frontier)的分析顯示,即便把多出來的這張 GPU 算進去,SSD 在每張 GPU 的吞吐效率上依然優於基線方案,也就是說並不只是靠堆硬件換速度。
整個推理優化領域正處在一個方法爆發期,SSD 的出現並不孤立。發表於 2025 年 3 月的 EAGLE 系列通過讓草稿模型以目標模型的內部表示爲條件來提升接受率;NVIDIA 在 2025 年 10 月的技術博客中專門介紹了 EAGLE-3 在其 GPU 上的部署實踐;SGLang 社區在 2025 年底也開源了 SpecForge 框架來訓練 EAGLE-3 草稿頭。
Together AI 自己則在 2025 年 12 月發佈了 ATLAS(AdapTive-LeArning Speculator System),一套能在生產環境中動態適應工作負載變化的自適應投機系統。Tri Dao 當時在採訪中提到,靜態投機器在工作負載發生漂移時效果會大幅下降,用戶從聊天切換到寫代碼,接受率就可能掉一截。ATLAS 的方向是讓投機器在運行時自主學習。
而 SSD/Saguaro 瞄準的則是另一個完全正交的維度:不是讓其猜得更準,而是讓猜測和驗證同時發生。論文也明確指出 SSD 可以和 EAGLE-3、token-tree 方法等組合使用,附錄 E 討論了 SSD-EAGLE-3 的組合方案,雖然存在草稿模型缺少目標模型激活信息的退化問題,但可以通過訓練草稿模型適應自我條件來緩解。
不過論文坦承,投機解碼整體上是一種“以計算換延遲”的策略,對於吞吐受限的場景,如大規模強化學習訓練中的數據生成、離線批量推理等並不適用,因爲驗證步驟本身就在消耗寶貴的 GPU 計算資源。SSD 在這個基礎上還進一步加大了計算開銷:草稿模型每輪需要爲 B×K×(K+1)×F 個 token 做解碼(B 是 batch size,K 是猜測長度,F 是扇出),比標準投機解碼的 B×K 多出了 (K+1)×F 倍。這些額外的 FLOP 投入在低延遲場景下可以被隱藏,在高吞吐場景下則可能成爲負擔。
另外,自定義注意力掩碼的構建和稀疏內存訪問模式也制約了草稿端可以做多少步有效推測,論文中大部分端到端加速來自於隱藏草稿延遲,而非增加猜測長度。
參考資料:
https://arxiv.org/abs/2603.03251
運營/排版:何晨龍



