

如果你有一塊 NVIDIA GPU,睡前啓動一個腳本,第二天早上醒來就能收穫一百次 LLM 訓練實驗的結果,其中一部分還確實比你手動調參調得更好,是不是聽起來有些難以置信?
但這就是 Andrej Karpathy 今天凌晨開源的新項目 autoresearch 所做的事。項目上線不到幾個小時,他在 X(原 Twitter)上的發佈帖瀏覽量突破百萬,GitHub 倉庫迅速收穫超過 2,500 顆星。整個倉庫的核心代碼只有約 630 行 Python。
圖丨相關推文(來源:X)
autoresearch 做的事情,一句話就能說清:把一個簡化過的大語言模型訓練環境交給 AI 智能體(AI Agent),讓它在你睡覺的時候自主跑實驗。智能體修改代碼,啓動訓練,五分鐘後檢查結果,如果驗證損失降低了就保留改動,沒降低就回退,然後繼續下一輪。你早上醒來,面前是一串實驗日誌,和一個可能變好了的模型。
過去幾年裏,Karpathy 開源了一系列以極簡主義著稱的項目:2020 年的 micrograd 和 minGPT,2023 年的 nanoGPT,2024 年用純 C 和 CUDA 寫的 llm.c,2025 年覆蓋 LLM 全流程的 nanochat,以及 2026 年 2 月那個僅用 243 行純 Python、零外部依賴實現 GPT 訓練和推理的 microgpt。每一次迭代都在做同一件事,剝除抽象層,把複雜系統壓縮到人類可以在一杯咖啡時間裏讀完的代碼量。
autoresearch 延續了這條線索,只是這一次,它不再是給人看的教學工具,而是給 AI 用的實驗平臺。
整個倉庫只有三個核心文件。prepare.py 負責下載訓練數據和訓練一個 BPE(Byte Pair Encoding,字節對編碼)分詞器,這個文件是固定的,智能體不能動。
train.py 是約 630 行的訓練腳本,包含完整的 GPT 模型定義、優化器(項目使用了 Muon 和 AdamW 的組合)和訓練循環,這是智能體唯一可以編輯的文件,模型架構、超參數、批大小、學習率,所有東西都可以改。
program.md 是一個 Markdown 文件,充當給智能體的指令手冊,由人類編寫和迭代。這裏的核心設計哲學是:人類編寫指導智能體行爲的"元程序",智能體負責編寫和修改實際的訓練代碼。
訓練的時間預算被硬性固定爲 5 分鐘牆鍾時間(wall clock time),不管你的硬件配置如何。這個設計選擇有兩個好處:
第一,不同實驗之間的結果可以直接比較,不管智能體把模型改大了還是改小了;第二,autoresearch 會爲你的特定硬件找到 5 分鐘內能達到的最優配置。代價是不同人在不同 GPU 上得到的結果無法互相對照。評估指標是 val_bpb(validation bits per byte,驗證集上的每字節比特數),越低越好,且與詞表大小無關,這樣即便智能體改變了分詞方案,實驗結果也能公平對比。
(來源:GitHub)
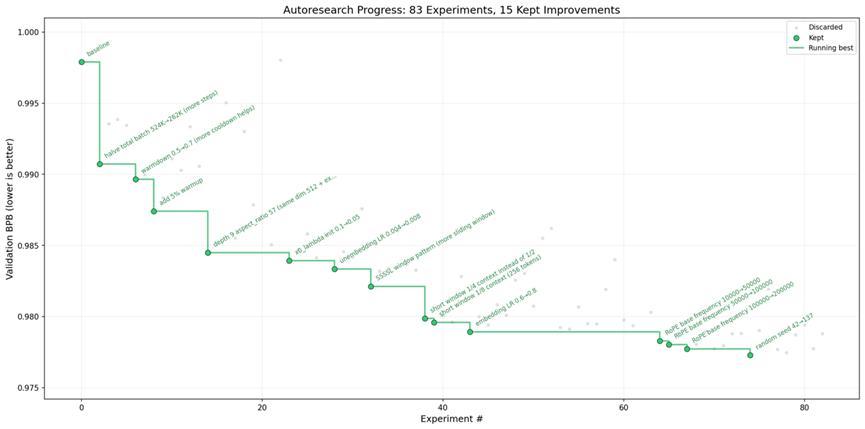
按照這個節奏,每小時可以跑大約 12 個實驗,一整夜大約 100 個實驗。Karpathy 在 README 裏附了一張圖:83 次實驗中保留了 15 次改進,驗證損失從接近 1.000 逐步下降到 0.975 附近。圖上每個點是一次完整的訓練運行,綠色點表示被採納的改動,灰色點是被丟棄的。
你可以看到智能體嘗試了各種各樣的策略,調整 batch 大小、修改學習率調度、切換激活函數、引入餘弦衰減等,有些管用,大多數沒用,但整體趨勢是持續向下的。
autoresearch 的訓練代碼來源於 Karpathy 在 2025 年發佈的 nanochat 項目的簡化版。nanochat 是一個覆蓋 LLM 全棧的實驗框架,從分詞到預訓練、微調、評估、推理到聊天界面全部包含在內,設計目標是在 8 塊 H100 GPU 組成的單節點上跑完全流程。
據 Karpathy 公佈的數據,用 nanochat 訓練一個 GPT-2 級別能力的模型大約需要花費 48 美元(約 2 小時的 8×H100 節點),而 2019 年 GPT-2 的訓練成本約爲 43,000 美元(nanochat GitHub,2025)。autoresearch 把 nanochat 進一步精簡到單 GPU 環境,砍掉了分佈式訓練、複雜配置和多階段流水線,只留下一個能跑、能改、能比較的最小單元。
智能體在一個 git 分支上工作。每當它找到一個更好的配置,就提交一個 commit。你可以在 git log 裏看到完整的實驗演化史。這種設計讓所有改動都是可審查和可回滾的,同時也構成了一份天然的研究日誌。Karpathy 建議使用 Claude Code 或 OpenAI Codex 這類代碼智能體來驅動實驗循環,並且把所有權限關掉,智能體只需要讀寫 train.py 和執行訓練命令的能力。
不過,這個項目目前只支持 NVIDIA GPU,測試環境是 H100。Karpathy 在 README 中坦承:支持 CPU、MPS(Apple Silicon)或其他平臺在技術上完全可行,但會讓代碼膨脹,而他不確定自己是否願意在這個方向上投入精力。他更傾向於讓社區來做 fork 和適配。
其實 AI 科研系統也並不算新鮮,但 autoresearch 和那些企業級或科研級系統之間有一個重要的區別:它是刻意做小的。Karpathy 沒有搭建一個多智能體編排框架,沒有設計複雜的通信協議,沒有引入什麼記憶模塊或檢索增強生成(Retrieval-Augmented Generation, RAG)管線。他做的事情和過去六年做的事情一樣,把一個概念壓縮到你能在週末下午讀完並跑起來的規模。一塊 GPU,一個文件,一個循環。
README 頂部有一段虛構的引言,大意是:將來 AI 研究完全由自主智能體集羣在天空中的計算集羣上完成,代碼庫已經經歷了 10,205 次迭代,變成了一個超越人類理解的自修改二進制程序,沒有人能驗證智能體對版本號的說法是否正確。Karpathy 標註的日期是 2026 年 3 月,然後附言:這個項目講的是這一切是如何開始的。
參考資料:
1. https://x.com/karpathy/status/2030371219518931079
2. https://github.com/karpathy/autoresearch



