

2025 年 9 月,美國孟菲斯,一座廢棄的家電工廠在 122 天內就被改造成了地球上最大的 AI 訓練集羣。xAI 的 Colossus 超級計算機首期部署 10 萬塊 NVIDIA H100GPU,到 2025 年底,整個園區目標算力推向 55 萬塊 GPU,功耗逼近 2GW。這大約相當於 150 萬戶美國家庭的負荷,或者阿姆斯特丹整個城市的電力消耗。
但問題是,孟菲斯當地的電網根本無法在短時間內接入如此龐大的用電負荷。於是在緊鄰孟菲斯的 Southaven,xAI 收購了一座廢棄電廠並架起數十臺燃氣輪機,配上大量 Tesla Megapack 儲能電池,最終實現了給 Colossus 超級計算機穩定供電的目標。
2026 年初,全球已有至少五座在建或規劃中的 GW 級數據中心,包括 Anthropic 與亞馬遜的 NewCarlisle、Meta 的 Prometheus、OpenAI 的 StargateAbilene、微軟在 Fayetteville 的項目。但是,每個項目都面臨同樣的問題:當地電網容量不夠,要麼排隊等待電網升級,要麼自己想辦法。
而這,還只是開始。對 AI 系統來說,真正稀缺的並不只是電力總量,而是可被穩定、低成本、高效率轉化爲有效算力的電力。
在大模型時代,單 token 能耗成本正成爲衡量算力效率、電力消耗與總體成本的核心指標。AI 的競爭並非停留在“誰有更多電”,而更在於“誰能把電轉化成更多的有效 token”。單位電力的 token 產出效率,將成爲 AI 時代的核心生產力。
過去,人們討論 AI,更多聚焦算力、模型和芯片;但當 AIDC(AI 數據中心)的負荷邁向 GW 級,AI 競爭的底層約束條件正在發生變化——誰不僅擁有算力,而且擁有穩定、低成本、綠色且可擴展的電力底座,誰才真正擁有下一輪 AI 擴張的門票。
AI 爭奪的,已經不只是“更多電”
AIDC 與傳統數據中心最大的不同,不在於規模,而在於其負荷特徵發生了根本變化。專爲 AI 訓練和推理設計的數據中心,通常具有三個顯著特徵:
其一,高功率密度。單機櫃功耗遠高於傳統數據中心,常常達到後者的 50 至 100 倍;
其二,7×24 小時高負載運行。對供電連續性和電能質量要求極高,哪怕毫秒級斷電,都可能讓價值數百萬美元的訓練任務前功盡棄。
其三,負載波動劇烈。AI 訓練任務啓動時,會帶來巨大的瞬時電流衝擊;這意味着,AI 對電力的需求早已不是簡單的“量”的問題,而是一個“質”的問題:不僅要有電,還要高可靠、高響應、高效率、可持續地供電。
因此,AIDC 的能源競爭,也正在從“有沒有電”轉向“如何用好每一度電”。
對於 AI 企業而言,真正關鍵的已不是獲取更多的電力資源,而是如何在單位電力消耗下,獲得更高的有效算力產出、更高的 GPU 利用率,以及更可控的全生命週期成本。電力不再只是算力的配套資源,而逐漸成爲決定算力效率、模型成本和商業可行性的核心變量。
據高盛預測,到 2030 年,全球數據中心電力需求將較 2023 年增長 165%,總裝機容量達到約 122GW。國際能源署(IEA)的判斷更爲直白:到 2030 年,數據中心年用電量將翻倍至約 945TWh,接近日本一年的電力消費總量。
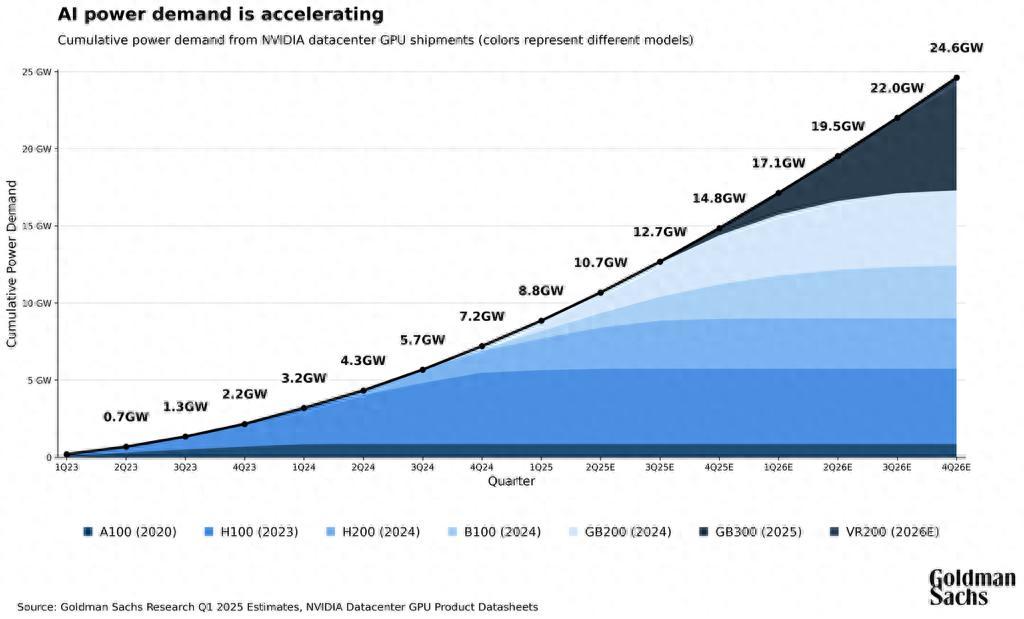
算力高速擴張的背後,AI 正把電力系統推向一個此前少有人認真討論過的邊界。
傳統電力系統爲什麼越來越難支撐新 AI
如果說 AI 數據中心的問題只是“缺電”,那答案其實並不複雜:多建電源、多拉線路、多上設備即可。
但現實並非如此。真正棘手的,不是某個局部場景“有沒有電”,而是現有電力系統能否以足夠快、足夠穩、足夠低成本的方式,支撐一種全新的負荷形態。
傳統電力系統的設計邏輯,建立在兩個前提之上:發電側相對可控,負荷側相對平穩。以集中式火電爲發電主力的舊式電力架構,更擅長處理可預測的供給與緩慢變化的需求,通過增加裝機、預留冗餘、依靠人工經驗調度來維持平衡。
但這套邏輯在今天正被雙重變化打破。
一端是供給側。2025 年 3 月,五部委出臺政策,提出到 2030 年,國家樞紐節點新建數據中心的綠色電力消費比例在 80% 基礎上進一步提升。隨着風電、光伏等可再生能源大規模併網,發電曲線越來越受氣象條件支配。電力供給不再主要來自少數幾個穩定運行的大型電廠,而轉向分散、碎片化、實時波動的風光資源網絡。
另一端是負荷側。AIDC 這類新型負荷不僅體量巨大,而且變化劇烈。GPU 集羣在訓練、推理、切換任務的過程中,會產生遠超傳統負荷特徵的功率波動;高密度疊加持續高負載運行,使其對電能質量、供電連續性和系統響應速度提出了近乎苛刻的要求。
也就是說,今天的電力系統,正同時面對兩類波動:一類是不可控的可再生能源波動,另一類是高頻、高強度、高敏感的 AI 負荷波動。
而傳統系統的主要應對手段,仍然是加大物理冗餘:擴建電網、增加後備電源、部署更多 UPS、提高設備規格、預留更厚的安全邊界。理論上,這些做法並非無效;但問題在於,它們越來越難以滿足 AI 產業的現實需求。
原因在於三點。
第一,速度不夠。AI 項目的部署節奏往往以月爲單位,而電網擴容、線路建設、審批和傳統基礎設施升級往往以年爲單位。二者在時間尺度上並不匹配。
第二,成本太高。單純依賴硬件堆疊和高規格冗餘,本質上是用大量資本開支和運行冗餘,去覆蓋高頻但不確定的風險。這種方法可以換來局部穩定,卻顯著抬高 AIDC 的建設和運營門檻。
第三,系統依然不夠聰明。硬件越堆越多,並不意味着系統就更理解波動、更能預判波動。它只是用更厚的“物理緩衝”去抵消複雜性,卻沒有真正提升系統的認知、判斷和協同能力。
這正是問題的關鍵所在:傳統電力系統難以支撐新 AI,不只是因爲系統承載能力有限,更因爲它很難以低成本、可複製的方式管理一個高度波動、強耦合的新型能源場景。
今天的矛盾,已經不是單純的“擴容問題”,而是一個系統智能問題。
當硬件堆疊走到極限,答案開始指向“物理 AI”
2025 年,黃仁勳在重返 CES 主舞臺的主題演講中,系統梳理了 AI 的演進路徑,並提出“物理 AI”概念 —— 過去十幾年,AI 經歷了感知 AI(讓機器學會“看”)、生成式 AI(讓機器學會“寫”和“畫”)兩個階段,現在正在進入第三個階段:物理 AI(Physical AI)。
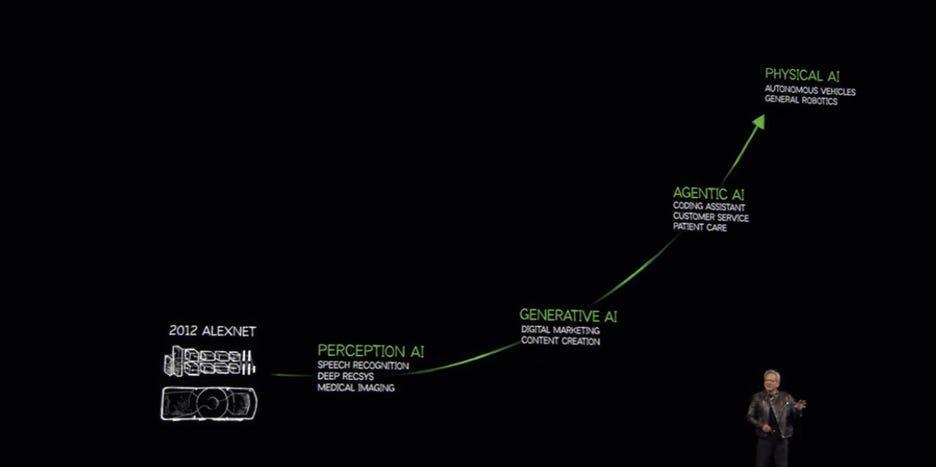
所謂物理 AI,是能夠理解物理世界規律、進行推理規劃並自主行動的 AI 系統。現行的大語言、圖像、視頻模型都無法理解和操控三維的物理世界。物理 AI 要處理的是重力、摩擦力、慣性、因果關係這些物理規律,讓機器在真實環境中感知、推理、決策和行動。
這一定義放到能源系統中,幾乎天然成立。
因爲能源系統本身就是一個典型的複雜物理系統。它不只是數據系統,也不只是軟件系統,而是一個實時運行、強耦合、強約束、零容錯的巨型基礎設施。頻率、功率、潮流、電池狀態、設備極限、氣象變化、電價波動——所有這些變量都不是抽象指標,而是真正決定系統安全與經濟性的物理現實。
在 2025年 CES 的半年之後,在一場以“人工智能與未來能源系統”爲主題的閉門科技會上,遠景科技集團董事長張雷發表演講,將物理 AI 的概念帶入了能源行業。他指出,這種“人腦難以駕馭”的複雜巨系統,恰恰是 AI 的絕佳戰場。“語言模型讀懂文字,物理人工智能讀懂世界,而能源是一切系統的基石。”

如果說黃仁勳關注的是如何讓 AI 擁有“身體”以感知物理世界,那麼張雷則敏銳地捕捉到了能源系統的邊界危機——傳統的“冗餘+人工”模式已無法承載一個高比例可再生能源、高波動負荷的新型電力系統。
這也是爲什麼,能源行業所需要的 AI,與聊天、寫作、圖像生成所依賴的 AI 並不相同。它不能“差不多”,更不能“生成一個大概正確的答案”。它必須在真實的物理邊界內運行,且每一步決策都要經得起設備約束和系統安全的檢驗。
從這個意義上說,AI 之所以成爲解決 AI 電力問題的關鍵,不是因爲“AI 很先進”,而是因爲它可能是少數能夠同時處理以下四類任務的工具:
它必須讀懂物理邊界:理解風光出力、電池狀態、設備極限和約束;
它必須實時感知與預測:在毫秒到分鐘級時間尺度上識別氣象、功率、出力等波動並預判趨勢;
它必須自主決策與優化:形成充放電、功率平滑、削峯填谷、電力交易等策略;
它還必須閉環執行,直接驅動真實設備完成響應,而不是僅停留在分析和建議層面。
換句話說,解決 AI 電力矛盾的,不會是一個更會“說話”的模型,而是一個更能“讀懂物理世界並採取行動”的系統。這正是物理 AI 的價值所在。
物理 AI 的另一半:沒有全棧,就沒有“物理”
行業中普遍存在一種數字化慣性思維:認爲只要算法足夠聰明,再疊加一層軟件,就能接管現實世界。
事實恰恰相反。物理 AI 的難點,從來不只是算力和模型,而是能否真正理解物理邊界,並把決策準確無誤地執行到物理系統之中。如果 AI 只是外掛在硬件之上的軟件層,它與真實設備之間就會始終隔着一層“認知斷層”:看得見數據,卻摸不到約束;算得出最優解,卻未必落得下去。
全棧能力,就是消除這道斷層前提。
所謂全棧,不是簡單地把硬件、軟件和算法堆在一起,而是讓 AI 從最底層的物理特性出發,向上貫通感知、控制、執行和優化的完整鏈條。只有掌握從感知元器件、動力執行器到核心算法模型的全路徑,AI 才能真正理解硬件極限,並在微秒級的瞬間做出不容置錯的決策,實現從“隔空指揮”到“具身智能”的飛躍。
這一點在能源領域,尤其在儲能場景中,體現得最爲極致。
儲能不是簡單的電池堆疊,而是一個橫跨電化學、電力電子與電網動力學的複雜物理系統。在 GWh 級儲能電站中,單站包含百萬級電芯。如果 AI 不掌握電芯的化學邊界,它在雲端計算出的“最優策略”可能加速電池衰減甚至引發安全風險;如果 AI 的指令要經過多層協議轉換才能抵達設備,毫秒級的延遲,足以讓系統在電網波動的瞬間失去支撐能力。
但算法再聰明,如果穿不透硬件,就與盲人摸象無異。
從公開信息來看,遠景是目前行業內少數具備儲能全棧能力的企業——從造電芯、做系統、寫算法,到全生命週期運營,形成一條完整的閉環。這意味着,AI 面對的不是一堆彼此割裂的零部件,而是一個可以被整體建模、整體調度、整體優化的系統。
它既能感知一顆電芯的健康狀態,也能理解一座電站對電網的支撐方式;它既能優化一次充放電的收益,也能把這種優化延伸到 25 年的安全運行與資產回報之中。
所以,儲能之所以成爲物理 AI 在能源領域最先落地的核心場景,不是因爲它“更需要概念”,而是因爲它最需要一種真正穿透物理邊界的智能。
AI 只有走到電芯、PCS、構網和電網協同這一層,纔不只是“更聰明”,而是開始真正成爲儲能系統的中樞神經。
只有這樣,儲能纔可能從被動的能量容器,變成能感知、能判斷、能響應、還能持續進化的智能資產。也只有這樣,在 AIDC 場景下,儲能纔可以從被動的備電設備,進化成一整套爲 AI 算力持續供電的能源底座。
一套“物理 AI”驅動的算力電力底座如何煉成
當行業還在討論“AIDC 該怎麼供電”時,有人已經把答案寫進了真實的項目裏。
在內蒙古赤峯,遠景與騰訊合作建成了全球首個 100% 綠電直供的數據中心。這個項目沒有接入一度火電,綜合能源成本降低超 40%,年碳減排達 18 萬噸。它正面回答了一個行業普遍認爲不可能的問題:零碳電力能不能撐住一座真實運行的數據中心?

圖|遠景攜手騰訊在內蒙古赤峯落地全球首個 100% 綠電直供的數據中心
答案是可以,但前提是一個被 AI 賦能的電力系統。
赤峯項目之所以能實現 100% 綠電穩定運行,依賴的不是堆砌更多的備用設備,而是一套貫穿“感知-預測-決策-執行”的智能調度體系。
遠景自研的天機氣象大模型持續預判風光出力變化,天樞能源大模型實時優化儲能充放電與負荷匹配策略,構網型儲能則在場站側主動支撐電網頻率和電壓。當風力驟降或負荷跳變時,系統不需要人工應急,而是在毫秒級完成策略調整。這正是物理 AI 在真實能源場景中閉環運轉的樣子——不是生成一個“建議”,而是直接驅動設備做出反應。
當 AIDC 的規模從百兆瓦級向 GW 級躍遷,單點技術的優化已遠遠不夠。遠景給出的系統方案覆蓋了四個層面:
一是全場景全鏈路方案佈局:在電網側,風光配儲綠電直連,縮短併網週期、壓低用電成本;在場站側,構網型儲能主動平抑負荷波動,穩定供電質量;在負荷側,直流儲能取代傳統 UPS,平抑毫秒級功率波動,保障算力設備穩定運行。
二是模塊化集成設計,支持快速擴展與便捷升級,可滿足百兆瓦級大型計算集羣的 EPC 交付需求;
三是全棧自研的軟硬件深度集成,實現供電鏈路效率最大化,大幅降低 AIDC 全生命週期的用電、運維成本;
四是極速交付能力,核心系統部署週期較行業傳統方案縮短 70%,可快速響應 AI 算力項目落地需求,匹配 AI 模型快速迭代的行業特性。
四層方案之間不是各自爲政,而是共用一套數據閉環。每一臺風機的出力數據、每一顆電芯的運行狀態、每一個時刻的電價信號,都在同一個系統中被感知、處理和響應。
這要求硬件和軟件必須在同一個體系內深度耦合,而這恰恰是遠景堅持全棧自研的原因。從電芯、PCS、BMS 到 EMS、SCADA,從氣象大模型到能源大模型,遠景在全球 400 餘座儲能電站、上億顆電芯的運行數據上持續訓練和驗證這套系統。
最終形成的是一個“AI 管理 AI”的閉環:物理 AI 保障電力系統的穩定、經濟與綠色,而穩定、低成本的零碳電力底座又爲 AI 算力的持續擴張提供源源不斷的動力。
從赤峯的落地案例來看,它所驗證的不只是一種技術方案,而是一種可能性:當能源系統具備了像算力一樣的柔性與智能,AI 產業的擴張纔不會被電力卡住脖子。
結語
AI 的盡頭是電力,而電力的未來,越來越像一個由物理 AI 驅動的智能系統。
在這個過程中,儲能不是唯一答案,但很可能是最先跑通閉環、最先形成產業規模的關鍵抓手。
而 AIDC 的能源競爭,也不會停留在“有沒有電”這個初級階段,而會越來越清晰地走向下一個問題:誰能以更低成本、更高穩定性、更強綠電能力,把每一度電真正變成有效算力。
運營/排版:何晨龍



