

知名 AI 圖像生成平臺 Midjourney 於 6 月 18 日正式發佈了其首個 AI 視頻生成模型 V1,這標誌着該公司從靜態圖像創作向動態多媒體內容生產的重大轉型,正式加入了由 Google、OpenAI 和 Runway 等科技巨頭主導的 AI 視頻生成競賽。
V1 支持用戶上傳現有圖像或使用 Midjourney 其他模型生成的圖像,由其生成一組四個 5 秒鐘的視頻片段。
在具體操作上,整個流程被設計得相當簡潔。用戶首先生成或上傳一張靜態圖像,然後點擊“動畫”按鈕即可將圖像轉換爲視頻。系統提供兩種工作模式:自動運動合成模式會智能分析圖像並添加適當的動畫效果,而自定義模式則允許用戶通過文本描述來精確控制場景中各元素的運動方式。
爲了滿足不同創作需求,V1 還提供了兩種運動強度設置。低運動模式專爲環境場景或極簡動畫設計,比如角色的眨眼動作或微風輕撫樹葉的效果,這種模式能夠產生更加自然細膩的動畫效果。
相比之下,高運動模式則會對主體和攝像機進行更加動態的處理,適合需要較強視覺衝擊力的場景,不過這也意味着可能出現更多視覺錯誤的風險。每個視頻任務會生成四個不同的 5 秒片段供用戶選擇,並且可以將每個片段延長 4 秒,最多可製作 20 秒的視頻內容。
定價方面,用戶可以通過訂閱 Midjourney 每月 10 美元的基礎計劃來使用 V1 功能,而訂閱每月 60 美元專業計劃和每月 120 美元超級計劃的用戶還能在“放鬆”模式下獲得無限制的視頻生成服務。與市場上其他產品相比,這一價格確實具有明顯優勢,比如 Runway 的標準計劃需要每月 15 美元,而 OpenAI 的 Sora 起價更是高達每月 20 美元。
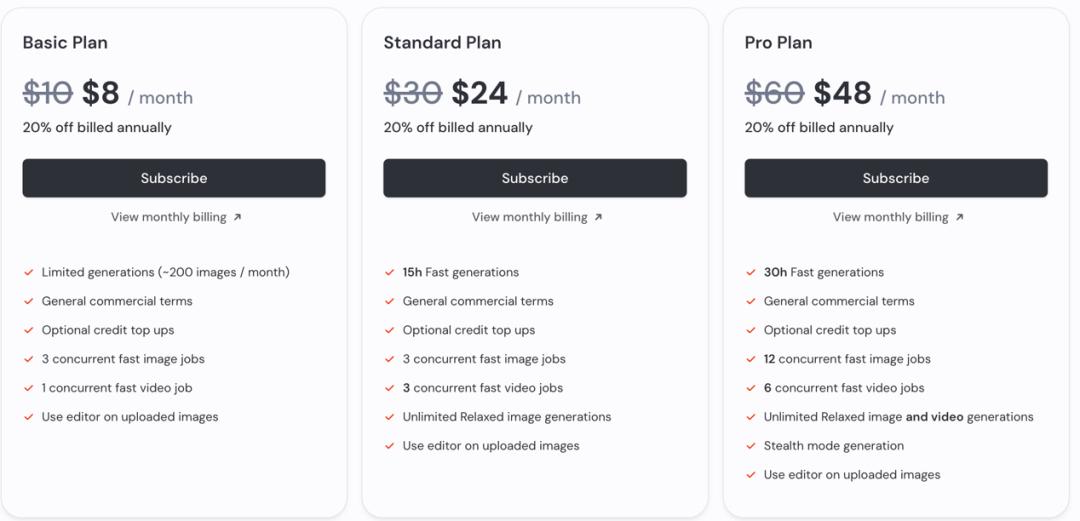
圖丨Midjourney 訂閱價格(來源:Midjourney)
從實測表現來看,V1 的初期表現還是不錯的。Perplexity AI 的設計師 Phi Hoang 在社交媒體上表示:“它超越了我所有的期望。”早期的演示視頻顯示,V1 生成的內容保持了 Midjourney 一貫的藝術風格,影像的總體質感看起來確實不錯。有許多網友都認爲其在卡通動畫風格上的表現突出。
圖丨相關推文(來源:X)
比如下面這個略帶黑色電影風格的動畫,看起來就非常流暢自然,對黑白光影的處理效果也很不錯。
不過,其對物理規律的理解和指令遵循能力似乎不算突出。比如在下面這個視頻中,對於擰瓶蓋這個動作的處理效果還是不太理想。
另外,V1 在功能完整性方面仍存在一些限制。最明顯的是該模型目前無法生成音頻內容,相比 Google 的 Veo 3 和 Luma Labs 的 Dream Machine 等競爭對手有所不足。用戶如果需要爲視頻添加配樂或音效,還需要藉助其他工具進行後期製作。此外,20 秒的時長限制以及缺乏時間線編輯、場景轉換等高級功能,也讓 V1 在專業應用場景中顯得有些力不從心。不過 Midjourney 方面表示,這只是初始版本,主要目的是測試市場反應和技術可行性,未來會逐步完善這些功能。
值得注意的是,V1 的發佈恰逢 Midjourney 面臨重大法律挑戰的時期。就在幾天前,迪士尼和環球影業在美國地方法院對 Midjourney 提起了全面的版權侵權訴訟。這份超過 100 頁的訴狀指控 Midjourney 在訓練其模型時未經授權使用了大量受版權保護的角色,包括漫威、星球大戰、辛普森一家和史萊克等知名 IP 形象。迪士尼和環球影業聲稱 Midjourney 創造了一個“抄襲的無底洞”,讓用戶能夠輕鬆生成包含艾莎、鋼鐵俠等角色的圖像。更值得注意的是,訴訟還特別提到了 Midjourney 的視頻服務,認爲這可能成爲未來更嚴重侵權行爲的溫牀。
這場法律糾紛的背景相當複雜。根據訴訟文件,Midjourney 在 2024 年的收入達到 3 億美元,服務用戶接近 2100 萬。迪士尼和環球影業認爲,該平臺正是建立在無償使用他人創意成果的基礎上才獲得瞭如此巨大的商業成功。迪士尼法務總監 Horacio Gutierrez 的表態頗爲強硬:“盜版就是盜版,AI 公司這樣做並不能讓侵權行爲變得不那麼嚴重。”這場訴訟可能會對美國版權法在 AI 訓練數據和輸出控制方面的應用產生重要影響,也可能迫使 Midjourney 等平臺在未來的內容過濾和授權協議方面做出重大調整。

圖丨相關新聞(來源:Reuters)
雖然面臨這些挑戰,但 Midjourney 對未來的願景依然雄心勃勃。在圍繞 V1 發佈的公開聲明中,公司透露了其長期目標:將靜態圖像生成、動畫製作、3D 空間導航和實時渲染技術融合爲一個統一的系統,也就是所謂的“世界模型”。這種系統將允許用戶在動態生成的虛擬環境中自由探索,視覺效果、角色行爲和用戶交互都會實時演化,就像沉浸式的視頻遊戲或 VR 體驗一樣。
他們設想的未來場景是,用戶可以簡單地說“帶我在日落時分穿越摩洛哥的集市”,系統就能生成一個可探索的交互式世界,完整呈現不斷變化的視覺效果,最終甚至包含動態生成的環境音效。
從這個角度來看,當前的 V1 更像是一塊重要的技術基石。Midjourney 將其稱爲通往更復雜 AI 系統的“技術踏板”,每一次技術迭代都在爲最終的願景積累必要的能力。
當然,V1 目前還遠未達到完美狀態。相比已經在市場上運營數月甚至數年的競爭對手,它在功能完整性和技術成熟度方面仍有明顯差距。但考慮到 Midjourney 在圖像生成領域建立的強大品牌影響力和用戶基礎,V1 的推出無疑爲這家公司開闢了新的增長空間。更重要的是,它也標誌着 AI 內容創作工具正在從單一媒體形式向多媒體融合的方向快速演進,這種趨勢將有望深刻改變內容創作的方式和門檻。
參考資料:
1.https://www.midjourney.com/updates/introducing-our-v1-video-model
2.https://techcrunch.com/2025/06/18/midjourney-launches-its-first-ai-video-generation-model-v1/
運營/排版:何晨龍



