

當 OpenAI 聲稱其 o3 模型在編程競賽中達到了 2700+ 的 Elo 評分,足以躋身全球頂尖選手行列時,一羣年輕的研究者卻給出了截然不同的答案。由多位華人 00 後奧林匹克競賽獲獎者主導、美國紐約大學助理教授謝賽寧參與的研究團隊推出了 LiveCodeBench Pro 基準測試,結果讓人大跌眼鏡:包括最先進的 o3-high、Gemini 2.5 Pro 在內的所有大語言模型,在困難級別的編程問題上無一例外地得了 0 分。
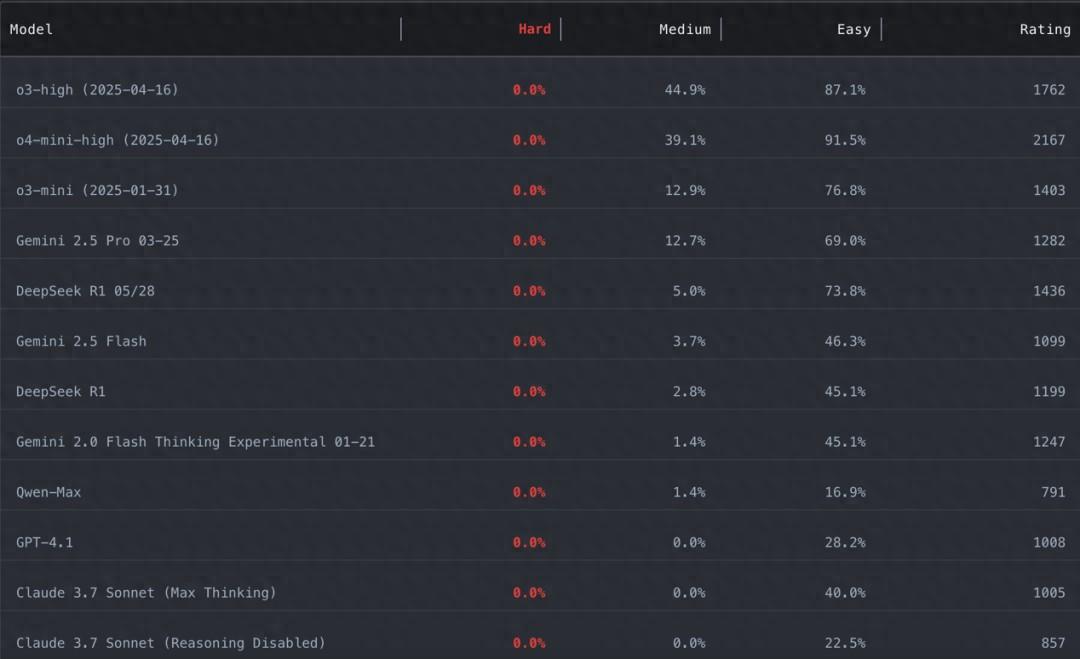
圖丨LiveCodeBench Pro 的實時排行(來源:LiveCodeBench Pro)
這個名爲 LiveCodeBench Pro 的測試由來自紐約大學、美國普林斯頓大學、美國加州大學聖地亞哥分校等院校的年輕研究者共同開發。團隊的核心成員包括多位在國際信息學奧林匹克競賽(IOI,International Olympiad in Informatics)中獲得獎牌的選手。

圖丨相關論文(來源:arXiv)
項目的主要負責人之一 Zihan Zheng 畢業於成都外國語學校,如今是紐約大學的一名本科生。另一位負責人柴文浩(Wenhao Chai)是浙江大學校友,即將前往普林斯頓大學就讀博士。還有 Zerui Cheng、Shang Zhou、Zeyu Shen、Kaiyuan Liu 等共同一作也大都是本科或直博在讀,甚至 Hansen He 目前還只是一名高中生。

圖丨Zihan Zheng(左);柴文浩(右)(來源:LinkedIn)
論文指出,現有的編程評測基準存在明顯缺陷,包括測試環境不一致、測試用例薄弱容易出現假陽性、難度分佈不平衡,以及無法隔離搜索污染的影響。LiveCodeBench 雖然提供了編程問題,但仍然受到這些問題困擾,而 CodeELO 等框架雖然專注於競賽編程,但依賴靜態檔案,難以區分真正的推理能力和記憶能力。
LiveCodeBench Pro 的獨特之處在於它的實時性和純淨性。研究團隊實時收集來自 Codeforces、國際大學生程序設計競賽(ICPC,International Collegiate Programming Contest)、IOI 等頂級賽事的最新題目,在任何解答或討論出現在網絡上之前就將其納入測試集。這種做法有效避免了數據泄露問題,確保模型無法通過記憶訓練數據中的答案來“作弊”。
截至 2025 年 4 月 25 日,LiveCodeBench Pro 共收錄了 584 道高質量編程題目,完全摒棄了 LeetCode 等相對簡單且容易被污染的題源。Zihan Zheng 還表示,每個季度他們都會發佈一個全新的評估集,其中包含該季度獨有的問題,以最大限度地減少污染並確保最新的基準測試。
測試結果令人相當意外。研究團隊將題目按 Codeforces 風格的 Elo 難度分爲三個等級:簡單(≤2000 分,世界級選手通常 15 分鐘內可解)、中等(2000-3000 分,需要融合多種算法和複雜數學推理)、困難(>3000 分,需要極其深刻的推導,連最強選手都可能無法解決)。
在最具挑戰性的困難級別上,無論是 OpenAI 的 o3-high、Google 的 Gemini 2.5 Pro,還是 DeepSeek 的 R1 模型,全部交出了 0 分的答卷。即使在中等難度的問題上,表現最好的 o4-mini-high 也只達到了 53.5% 的通過率,而 Gemini 2.5 Pro 僅爲 25.4%。
值得注意的是,研究團隊計算了模型的 Codeforces 等效 Elo 評分。o4-mini-high 的評分爲 2116,雖然聽起來不錯,但這僅能排在所有人類參賽者的前 1.5%,遠達不到“超越精英人類”的水平。OpenAI 宣稱的 2719 評分與實際測試結果之間存在約 400 分的差距,研究者推測這主要歸因於工具調用和終端訪問等外部輔助的作用。
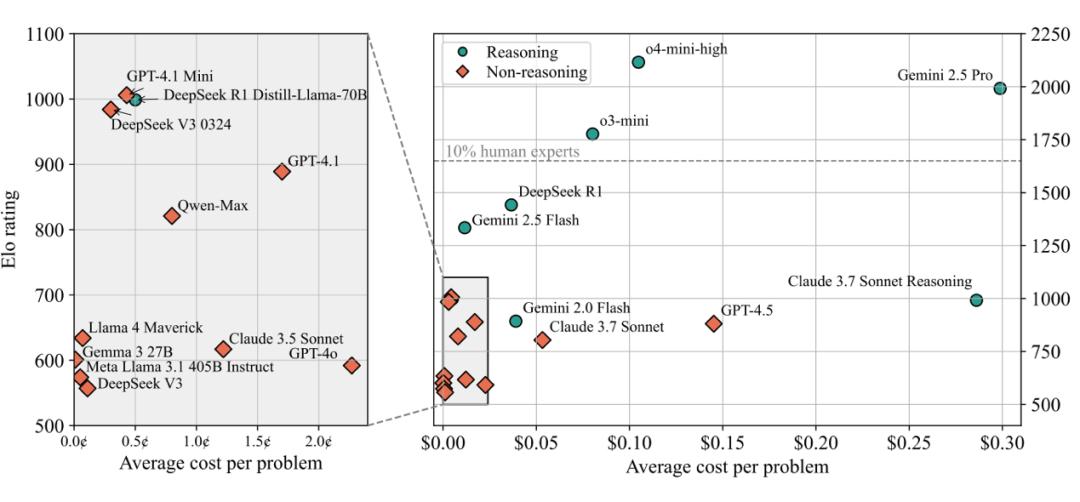
圖丨LiveCodeBench Pro 排行榜(來源:arXiv)
爲了深入理解模型的能力邊界,研究團隊創新性地將編程問題按認知重點分爲三類。知識密集型問題主要考查對算法模板和數據結構的掌握,這類問題的解答往往需要現成的代碼模板,比如快速傅里葉變換的應用。在這類問題上,模型表現相對較好,因爲相關內容在訓練數據中大量存在。

圖丨知識密集型問題示例(來源:arXiv)
邏輯密集型問題需要系統性的數學推理和逐步推導,如組合數學和動態規劃,要求將符號操作轉化爲高效算法。

圖丨邏輯密集型問題示例(來源:arXiv)
觀察密集型問題則需要從問題描述中敏銳地捕捉關鍵洞察,往往一個“頓悟”就能讓複雜問題迎刃而解。

圖丨觀察密集型問題示例(來源:arXiv)
測試結果顯示,模型在不同類型問題上的表現差異巨大。在線段樹、圖論、數據結構等知識密集型問題上,多數模型都能達到相當水平,這些問題本質上考驗的是代碼實現能力和算法庫的掌握程度。在組合數學、動態規劃等邏輯密集型問題上,模型表現中等,能夠進行一定程度的邏輯推理。
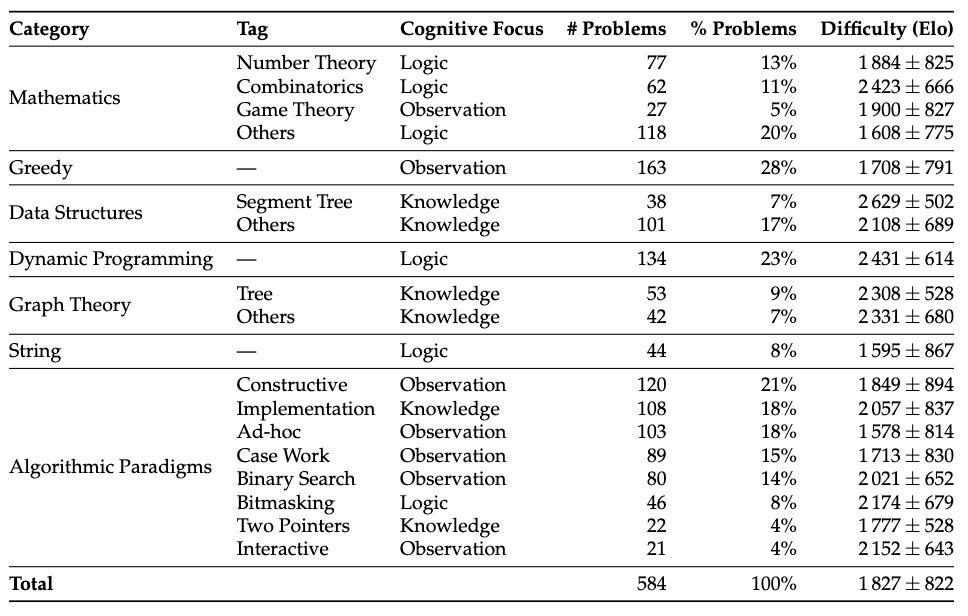
圖丨LiveCodeBench Pro 統計數據,針對帶有相應認知焦點分類的已標註標籤。(來源:arXiv)
但在博弈論、貪心算法、構造類等觀察密集型問題上,幾乎所有模型的 Elo 評分都跌破 1500,表現慘不忍睹。特別是在需要處理邊界情況(case work)的問題上,除了 o4-mini-high 外,其他模型的評分都在 1500 以下,顯示出模型在識別和處理邊界條件方面的顯著不足。
研究團隊還進行了細緻的錯誤分析,他們逐行對比了 125 個 o3-mini 模型的失敗提交和同等水平人類選手的失敗提交。結果發現,o3-mini 在算法邏輯錯誤和錯誤觀察方面的失誤比人類多出 34 次,這些是真正的概念性錯誤,而非表面的程序錯誤。
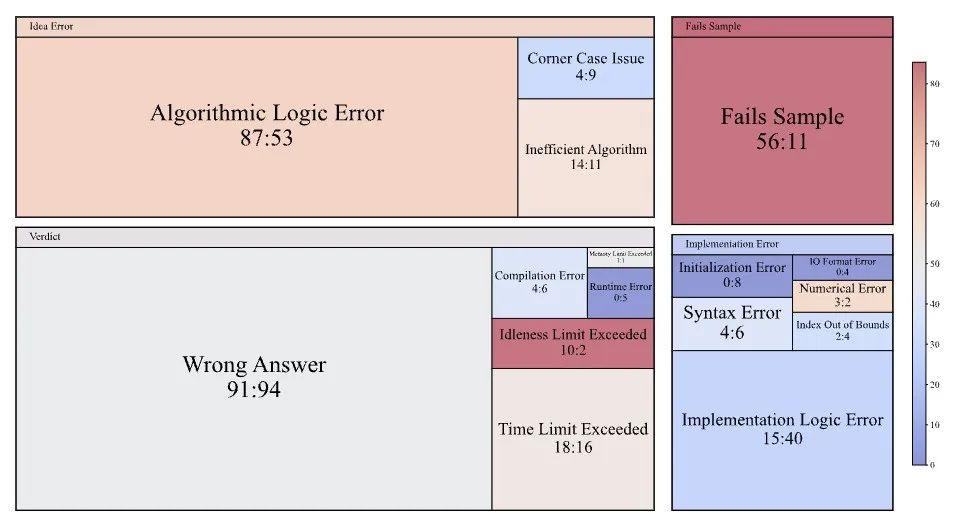
圖丨比較 o3-mini 和人類提交被拒絕的原因(來源:arXiv)
但在實現層面,o3-mini 的表現明顯優於人類,實現邏輯錯誤比人類少 25 次,所有觀察到的初始化錯誤和輸入輸出格式錯誤都出現在人類提交中,模型幾乎不會出現“運行時錯誤”。這說明模型的編程語法和代碼實現能力確實不錯,但在覈心的算法設計和問題理解上存在根本性缺陷。
更要命的是,o3-mini 有 45 次在樣例輸入上就失敗了,而人類選手在提交前通常會先在本地測試樣例。這暴露了模型無法有效利用給定信息的問題,連最基本的驗證都做不好。與此形成對比的是,具備終端訪問和工具調用能力的模型 (如 o3 和 o4-mini-high 的完整版本) 預期會大大減少這類容易發現的錯誤。
在推理能力的測試中,研究團隊專門對比了 DeepSeek V3 與 R1、Claude 3.7 Sonnet 的普通版與推理版之間的差異。結果顯示,推理功能在組合數學問題上帶來了最大提升,DeepSeek R1 相比 V3 在此類問題上提高了近 1400 個 Elo 點。在數據結構、線段樹等知識密集型問題上,推理也帶來了顯著改善,這符合預期,因爲這些問題往往需要結構化思維。但在博弈論、貪心、構造等觀察密集型問題上,推理的幫助微乎其微,有時甚至是負面的。這說明當前的鏈式思考技術雖然能加強邏輯推導,但對培養算法直覺和創造性洞察力作用有限。
業界常用的 pass@k 評估方法允許模型多次嘗試同一問題,取最好結果。在 LiveCodeBench Pro 上,這種方法確實能顯著提升模型表現。o4-mini-medium 的評分從單次嘗試的 1793 提升到 10 次嘗試的 2334,類似的提升在其他模型上也很明顯。研究發現,在獲得最大改善的五個類別中,有三個——博弈論、貪心和邊界處理——都屬於觀察密集型問題,這些問題往往可以通過假設驗證來解決,多次嘗試大大增加了猜中正確答案的概率。但即使給予多次機會,模型在困難問題上的通過率依然爲零,表明這些問題的難點不在於偶然的實現錯誤,而在於根本性的算法理解缺失。
測試中還發現了一個有趣現象:o4-mini-high 在交互式問題上的表現異常糟糕,Elo 評分跌至 1500 左右,其他模型表現也很差。交互式問題要求程序與評測系統進行多輪信息交換,需要對問題有深刻理解才能設計正確的交互策略。研究團隊發現,模型經常因爲“空閒時間超限”而失敗,說明它們無法理解交互的時機和策略。
從成本角度來看,LiveCodeBench Pro 統計顯示,最昂貴的模型未必表現最好。Claude 3.7 Sonnet 推理版平均每題花費 0.29 美元,但 Elo 評分僅爲 992,性價比很低。相比之下,一些較便宜的模型反而表現更穩定。o4-mini-high 由於推理鏈條過長 (最多 10 萬 token) 和成本高昂(約 200 美元每次完整測試),研究團隊只能限制其在 pass@3 設置下進行評估。
這些發現表明,儘管大語言模型在代碼生成和簡單編程任務上表現出色,但在需要深度算法思維的複雜問題上仍有很長的路要走。正如論文所指出的,當前模型的高性能很大程度上依賴於實現精度和工具增強,而非卓越的推理能力。在算法創新和問題洞察這些人類智慧的核心領域,AI 仍然無法與頂尖的人類專家相提並論。
參考資料:
1.https://livecodebenchpro.com/
2.https://arxiv.org/abs/2506.11928
運營/排版:何晨龍



