

你有沒有想過:DeepSeek-R1 這類大型推理模型是如何自主學會思考的?
爲尋找這一問題的答案,中國科學院理論物理研究所陳錕副研究員團隊與合作者對 DeepSeek 強化學習算法的動力學機制展開深入研究。他們發現,在單個訓練樣本的條件下,該算法導致的湧現行爲可以用複雜網絡中的相變現象來精準描述。
基於這一重要發現,他們提出了“臨界學習”(LaC,Learning at Criticality)的理論框架,其核心思想是:通過強化學習的優化機制,將大模型參數調整到一個關鍵的臨界狀態,當模型處於這個臨界態時,能夠從極少量的訓練數據中實現最佳的泛化性能。不僅能從極少量學習樣本中抽象出通用算法規則,甚至僅憑單個示例即可實現複雜數學運算和量子場論中的符號推導等高階認知任務。

圖丨陳錕(來源:陳錕)
傳統 AI 方法從海量多樣化問題中學習,以保持泛化能力和發現不同問題之間的共性。與之不同的是,LaC 方法模擬了人類專家在專業領域的研究範式——通過深度聚焦單個複雜問題,經歷反覆的思考與試錯過程來獲得突破性解決方案。
“臨界學習”方法的創新性主要體現在突破傳統 AI 在基礎科學領域的三大侷限:首先,解決了數據稀缺條件下的學習效率問題;其次,克服了高度專業化知識獲取的障礙;最後,實現了小樣本情況下的深度專業化學習,這一點對於數據稀缺的基礎科學研究尤爲重要。
陳錕對 DeepTech 表示:“傳統 AI 方法往往受限於數據規模,LaC 爲應對理論物理、數學證明、材料設計等領域中複雜且數據稀疏的挑戰提供了新的 AI 解決方案。未來,隨着 LaC 理論的進一步完善,它有可能不侷限於優化 AI 的推理能力,更有望爲理解大模型中複雜推理能力的湧現機制提供新的理論工具。”
同時,該方法在基礎科學中的應用或將催生新的研究模式,有助於推動 AI 研究範式從作爲輔助工具的 AI for Science 逐步演變爲“自主探索科學問題的智能體”,從而真正實現 AI for Fundamental Science。
近日,相關論文以《大型推理模型的臨界態學習及其在量子場論等領域中的應用》(Learning-at-Criticality in Large Language Models for Quantum Field Theory and Beyond)爲題發表在預印本網站 arXiv 上 [1]。
中國科學院理論物理研究所博士後蔡賢盛和中國科學技術大學胡思寒博士生是共同第一作者,美國麻省大學阿默斯特分校王韜博士、深勢科技黃遠博士、中國科學院理論物理研究所張潘研究員、中國科學技術大學鄧友金教授以及中國科學院理論物理研究所陳錕副研究員擔任共同通訊作者。

圖丨相關論文(來源:arXiv)

受物理啓發的臨界突破:將複雜問題簡化成“真空球形雞”
今年 1 月,隨着 DeepSeek 發佈其推理模型 DeepSeek-R1 並在全球引發廣泛關注,長期專注於多電子場論研究的陳錕團隊敏銳地注意到一個關鍵科學問題:與傳統 AI 系統(如 Alpha Zero 依賴人工設計的蒙特卡洛樹搜索)不同,DeepSeek 模型展現出自發形成推理式思考模式的能力。這一現象激發了團隊的研究興趣——DeepSeek 是如何自主學會思考的?
陳錕解釋說道:“作爲物理研究者,我們對這種湧現現象特別敏感,這讓我聯想到可以嘗試用統計物理的理論框架來解析這一過程。”
在研究過程中,團隊通過分析模型的推理模式,提出了一個關鍵假設:DeepSeek 背後可能存在一個簡約而普適的物理模型。他們發現,當模型學習單一問題時,其自發湧現過程表現爲典型的臨界物理現象特徵,類似於水-水蒸氣的相變過程。然而,由於實際訓練涉及多問題場景,其湧現模式又呈現出更復雜的特徵。
發現這一有趣的現象後,研究團隊繼續思考:這樣的物理現象與傳統的機器學習方法有何本質區別?他們逐漸意識到,這可能代表了一種全新的、將 AI 應用於科學研究的範式,有望爲解決基礎科學中需要深度思考的問題提供新思路。
這一推理能力相變的理論,來源於陳錕團隊對於模型如何學習多位數加法問題的深入研究。團隊首先選擇 7 進制多位數加法(7 位數)作爲測試基準。實驗顯示,未經訓練的 Qwen2.5-7B 模型完全不具備解決該問題的能力,但通過基於單樣本的強化學習訓練後,模型最終能夠以接近 100% 的準確率解決這一樣本問題,其學習曲線並不是隨着訓練步驟線性增加,而是在一定訓練步驟後出現躍升的相變行爲。
進一步實驗發現,相變點附近的模型雖然對於訓練樣本的準確率尚未達到峯值,但是模型在其他多位數加法問題上,由於模型發展出批判性思維特徵,反而表現出最強的泛化能力。
這表明,大模型在臨界點運行時達到最優性能平衡:既能保持探索的靈活性,又能提取底層操作規則;而過度的訓練反而會使模型思維僵化,喪失批判性思考能力。
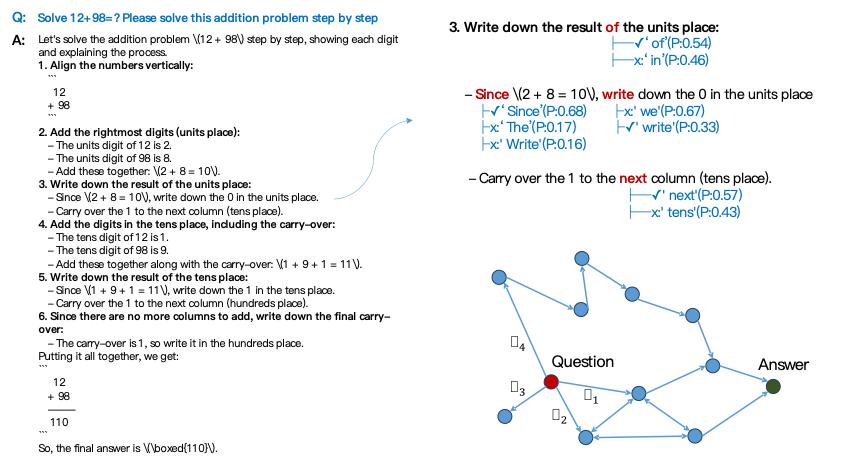
圖丨當大模型回答“12+98=?”問題時的推理過程(來源:陳錕)
基於這些發現,研究團隊從模型推理的細節入手,構建起一套獨特的理論框架。該理論來自一個有趣的觀察,當大模型回答例如“12+98=?”這類問題時,標準的推理過程會逐個輸出 token,而這其中“暗藏玄機”:有些詞的出現幾乎是必然的,比如回答中“結果”前大概率是“正確的”;而有些詞則充滿不確定性,如“結果”後接“of”還是“in”,模型會陷入短暫的“糾結”。
團隊將這些充滿不確定性的 token 位置定義爲“決策點”,確定性 token 序列抽象爲“概念”(Concept),並通過決策點間的關聯構成“概念網絡”(CoNet),以此建模大模型思考過程中的決策空間。
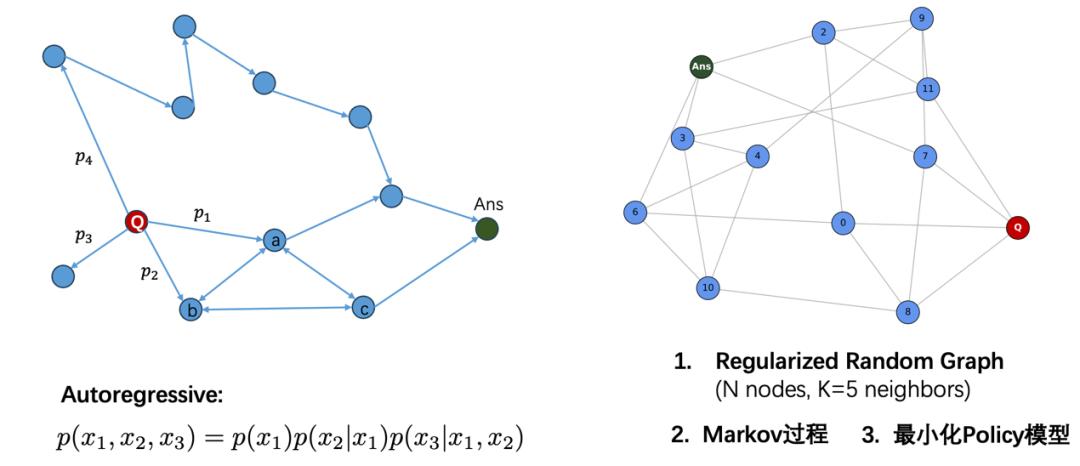
圖丨左:大模型思考的隨機行走;右:最小化 Policy 模型(來源:陳錕)
在該理論中,大模型長思維鏈中的抽象推理(System 2)過程對應於概念網絡中的隨機行走(如上圖左):模型從問題語境出發,通過探索網絡路徑最終抵達答案。其中,路徑選擇的概率分佈至關重要:過於均勻的分佈導致思維發散難以收斂,而過度確定的分佈則易陷入局部最優。
研究人員發現,DeepSeek 的 GRPO 強化學習算法和其變種,正是通過調節每條路徑的概率,使得網絡處於一箇中間態。如果通過單個學習樣本訓練,這一中間態處在一個連續相變點附近,表現出臨界行爲;如思考的路徑長度呈冪律分佈(P(L)∼L⁻⁰·¹⁶),模型兼具“尋找最短路徑”的高效性與“探索多樣路徑”的靈活性,這種狀態下的模型泛化能力最強。這種無標度使得模型同時發現高效路徑與備選策略,是“臨界思考模式”的物理基礎。
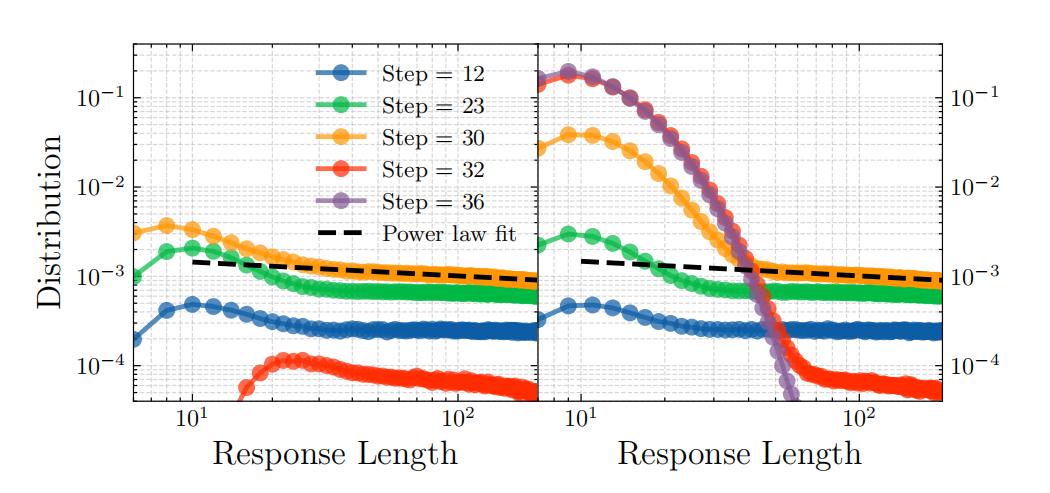
圖丨獨特的推理動態:關鍵冪律搜索過渡至收斂後指數探索階段(來源:arXiv)
陳錕表示,臨界學習的方法深受物理啓發。就像當物理學者面對複雜問題時,通常會先將其簡化爲“真空球形雞”理想模型。這種從簡化模型出發,再逐步擴展到複雜系統的研究路徑,爲理解大模型的認知機制提供了全新的方法論視角。
研究團隊從簡化模型反推真實大模型,也發現了相似的相變行爲,由此提出“臨界學習”方法:通過單個訓例把網絡訓練到臨界態,能夠在數據極度稀缺的情況下,實現具有泛化能力複雜長思維鏈推理的學習。
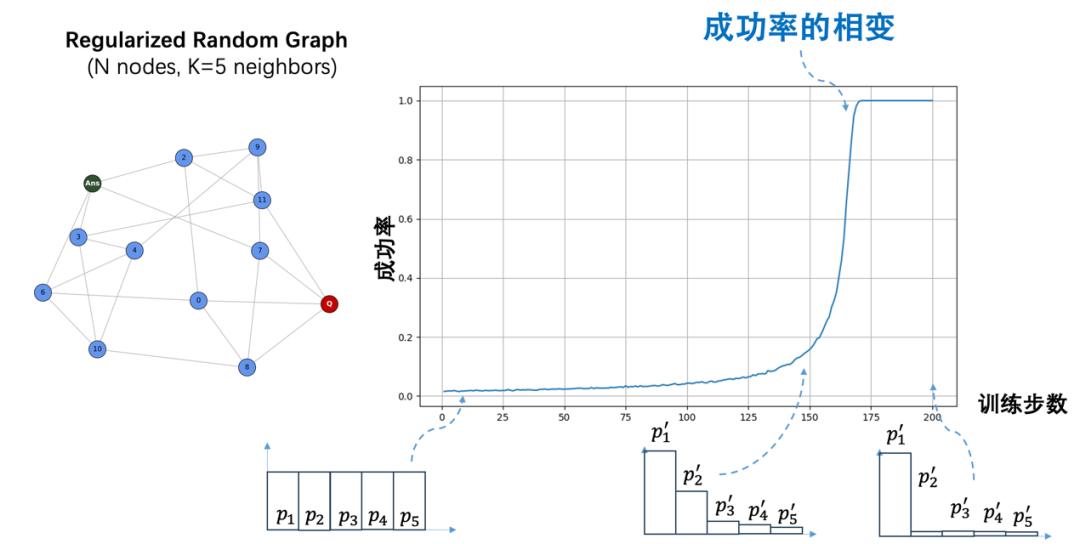
圖丨簡易模型中的強化學習動力學(來源:陳錕)
在 DeepSeek-R1 671B 模型發佈後,研究團隊系統評估了其在理論物理領域的能力表現,發現其水平相當於高年級本科生至中低年級研究生,但對更復雜問題仍存在侷限。這促使他們思考,或許可以借鑑培養研究生的方法——通過深度思考逐步攻克複雜問題。
基於此,研究團隊選擇在理論物理中的典型問題——計算高階不同圈的費曼圖進行 LaC 的效果驗證。他們利用 80 億參數的 Qwen3-8B 模型,分階段訓練其求解松原頻率求和問題。
值得關注的是,僅通過低階圖例進行臨界點訓練,模型可成功推導出未見過的高階圖解,其表現甚至優於參數量高兩個數量級的基準模型。
數據顯示,經過 LaC 訓練的模型在 1-loop 和 2-loop 圖上的準確率分別達到 97.5% 和 56.9%,並能泛化至 3-loop 和 4-loop 問題,而未經訓練的基準模型在這些任務上表現不佳。

表丨關鍵學習躍遷實現松原求和的泛化能力,8B 模型⼤幅超越 671B 模型(來源:arXiv)

有望突破數據稀缺瓶頸,爲科研範式革新提供新的可能性
當前 AI 系統面臨的關鍵瓶頸在於其靜態的知識體系架構,這與人類持續進化的終身學習能力形成鮮明對比。要實現類似人類的知識迭代機制,AI 系統需要發展出“增量學習”能力,即通過持續的環境交互積累數據並動態優化模型參數。然而,這種學習模式本質上受制於數據稀缺問題,這使得基於 LaC 的小樣本學習技術成爲突破這一困境的關鍵所在。
在科學應用層面,LaC 方法對基礎科學的推動體現在多個方面。以化學研究爲例,專注特定反應數十年的實驗室積累了極其專業化的知識體系,這類深度知識往往超出通用大模型的掌握範圍。針對這種情況,採用 LaC 基學習策略展現出顯著優勢:通過讓模型集中攻克領域核心問題,在確保專業知識深度的同時保持必要的泛化能力。
傳統研究模式下,博士生通常需要投入半年至一年時間才能掌握前沿場論問題的兩圈費曼圖(2-loop Feynman diagrams)的解析計算方法,而當問題複雜度提升至三圈圖(3-loop Feynman diagrams)時,人工計算幾乎不可行。歷史上,量子電動力學三圈散射圖的解析計算曾耗費學界數十年時間,而這類問題恰恰是 AI 技術可以“大顯身手”的領域。
雖然 AI 在學習高圈費曼圖時同樣面臨嚴峻挑戰,然而一旦突破這一專業瓶頸,就可能展現出強大的知識遷移能力,解決因人類認知侷限而長期停滯的科學難題。通過這種專業化深度與泛化廣度的有機結合,AI 系統有望發展成爲突破人類認知邊界的“專業智能體”。
“在研究 DeepSeek 強化學習算法的過程中,我們發現這是一個極具科學價值的探索方向。我們希望能利用在相變等多體統計物理等方面的專業積累,深入解析這一現象背後的物理機制。”陳錕說。
基於這一目標,研究團隊確立了雙向研究路徑:Physics for AI(運用物理學原理理解 AI)和 AI for Physics(運用 AI 技術推動物理學發展)。
在 Physics for AI 方向,團隊目前已完成第一階段工作,即通過單個問題的問答學習研究相關物理現象。後續研究計劃深入探討更復雜的科學問題:在多問題學習場景下,模型的網絡結構會呈現怎樣的動力學特徵?是否仍然存在臨界物理現象?對這些機制的深入理解,不僅可能爲強化學習算法的優化設計提供理論指導,還有助於評估現有算法的性能上限。
在 AI for Physics 方向,團隊採取的策略是將開源大模型視爲“科研新生”,通過針對理論物理等特定領域的強化訓練,系統探索將其培養成爲專業科研助手的可行性。這一研究思路既借鑑了人類專家的培養模式,又充分發揮了 AI 在數據處理和模式識別方面的獨特優勢,爲科研範式的革新提供了新的可能性。
參考資料:
1.https://arxiv.org/abs/2506.03703
運營/排版:何晨龍



