

一個在 1,000 萬個太陽系相關數據上訓練的 Transformer 模型能夠精準地預測行星軌道,卻對引力定律一竅不通。那麼,預測模型和世界模型有什麼區別?是否存在簡單直接的指標可以檢驗這種差異?來自美國哈佛大學和美國麻省理工學院的研究人員認爲,或許最具影響力的世界模型,最初正是從一個預測模型起步的。

(來源:https://x.com/keyonV/status/1943730502948511937)

當開普勒和牛頓“遇見”AI
爲了研究上述 AI 問題,他們追溯到了 400 年前的科學成果。在英國科學家艾薩克・牛頓(Isaac Newton)於 17 世紀提出萬有引力定律之前,德國天文學家約翰內斯・開普勒(Johannes Kepler)的行星軌道預測模型早已存在,開普勒的預測促成了牛頓萬有引力定律的發現。
而本次研究團隊認爲,基礎模型的前景依賴於這樣一個核心假設:學習預測序列能夠揭示更深層次的規律,甚至樂觀地說其能構建出一個世界模型。雖然從某種意義上說這個想法是新穎的,但從另一種意義上說它又是古老的。
如前所述,數百年前開普勒發現了一些幾何規律,藉助這些規律能夠精準預測夜空中行星未來的位置。牛頓後來在這一進展的基礎上發展並創立了牛頓力學,這些基本定律不僅能夠預測行星的運動,還能解釋宇宙中的各種物理特性。這條“從預測序列到理解其背後深層機制”的路徑,並非物理學所獨有。在生物學領域,動物育種者們早已觀察到後代性狀的規律,而他們這些具有預測性的見解,啓發着奧地利帝國生物學家格雷戈爾・約翰・孟德爾(Gregor Johann Mendel)提出了遺傳學理論。
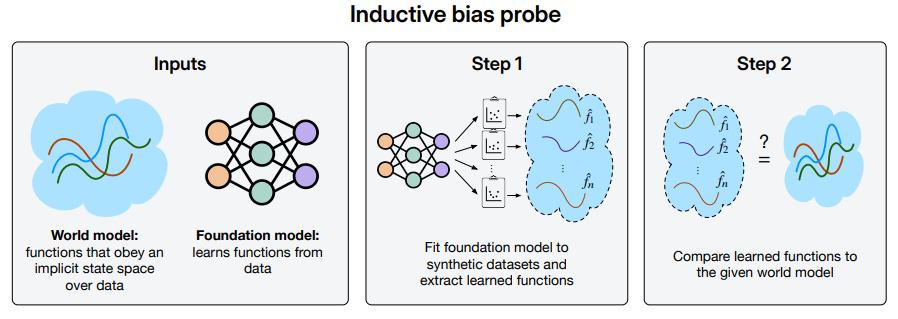
如何才能知道基礎模型是否也已實現“從做出準確預測到構建可靠世界模型”的跨越?本次研究通過構建一個框架來回答這個問題。
具體而言,研究團隊開發了一種檢測框架:當給定基礎模型和世界模型時,該框架能夠驗證基礎模型是否已經習得目標世界模型。研究團隊將這種技術稱爲歸納偏置探針,它基於這樣一個簡單的見解:基礎模型的隱性世界模型會通過“其如何從少量信息中進行推斷”而顯現出來,即從少量數據中做出推斷。同樣,基礎模型的歸納偏置也能揭示其世界模型。
(來源:https://arxiv.org/pdf/2507.06952)

靈魂一問:模型是否掌握了牛頓力學?
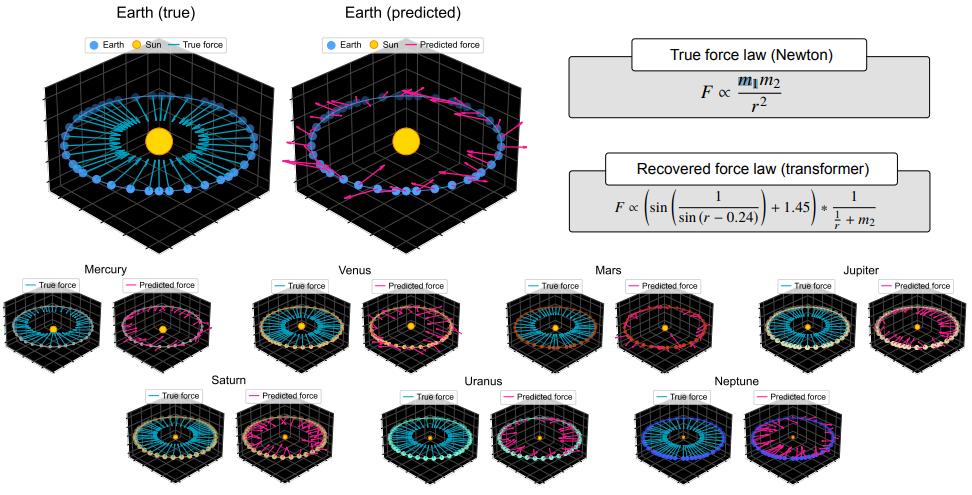
研究中,研究團隊通過以下實驗來驗證相關觀點:他們測試一個經過行星運動位置預測訓練的 Transformer 模型是否真正掌握了牛頓力學體系。具體來說,他們首先訓練一個模型來預測太陽系中行星的位置。儘管該模型能夠準確預測行星的未來軌跡,但是歸納偏置探針表明它對牛頓力學的歸納偏置較低。
比如,當對該模型進行微調以便預測行星的力向量(牛頓力學的核心要素)時,其預測結果所隱含的引力定律是毫無意義的。研究團隊發現,該模型所習得的是零散的啓發式方法,而非一個簡潔的世界模型,它會根據所應用的數據片段採用不同的引力定律。
幾個世紀以來,天文學家和物理學家一直致力於預測行星圍繞太陽運行的軌道。開普勒提出了一個具有開創性的模型,他的模型基於幾何圖案而提出:例如,每個行星的軌道都遵循一個橢圓,而太陽位於該橢圓的一個焦點上。儘管該模型能夠以近乎完美的精確度預測軌道,但它無法解釋行星爲何遵循這些幾何軌道,也無法應用於預測軌道之外的新問題。
後來,牛頓利用新的運動定律對上述模型進行了拓展,這些定律現在被稱爲牛頓力學。這些定律涉及到計算運動中行星羣的各種屬性,例如它們的相對速度和質量。利用這些特性,不僅能夠推導出開普勒早先提出的軌道運動定律,也能進一步理解力與引力等核心物理概念。
可以說,從開普勒到牛頓,科學家們實現了從序列預測模型到深層理論認知的跨越。本次研究之中,研究團隊測試了一個能夠預測軌道軌跡序列的 Transformer 模型,以便探究它究竟僅僅是一個優秀的序列模型?還是已經實現了向世界模型的轉變?
爲此,研究團隊模擬了一個序列數據集,其中每個序列都描述了行星繞太陽運行的情況。他們隨機採樣初始條件(例如行星的質量、位置及其初始相對速度),以便匹配在已知系外行星中觀察到的軌道形狀。同時,他們根據牛頓運動定律模擬每顆行星圍繞太陽的軌跡。
由於行星的質量遠遠小於太陽,因此行星之間的相互作用微乎其微,所以忽略不計這些相互作用。爲了將軌道轉換爲序列,研究團隊每隔一定時間記錄一次每個行星和太陽的(x,y)座標,並將所有位置交錯排列成一個包含 1,000 個觀測值的序列,這意味着每個序列代表一個不同的太陽系。
(來源:https://arxiv.org/pdf/2507.06952)
此外,研究團隊考慮了兩種不同類型的時間間隔:固定間隔和變化間隔。在固定間隔中,每個序列使用相同的 6 個月間隔;在變化間隔中,隨機一半的序列使用 6 個月間隔,另一半使用1周間隔,並在開始處添加一個特殊 token 以用於指示間隔長度。
例如,在一個擁有 K 個行星且時間間隔各異的太陽系中,第一個時間步長編碼了時間間隔的長度,接下來的 K 個觀測值是每個行星在第一個時間點的(x,y)座標,再接下來的 K 個觀測值是每個行星在相應時間步長後的座標,以此類推。
同時,研究團隊設置了兩種訓練集規模:第一種是固定間隔數據集,擁有 10 億 token、涵蓋 100 萬條序列;第二種是可變間隔數據集,擁有 200 億 token、涵蓋 1,000 萬條序列。針對這兩種情況訓練的模型,得出了相似的結果。
接下來,研究團隊訓練了一個包含 1.09 億個參數的 Transformer 模型,以用於預測訓練集中每個序列的下一個 token。他們在以下兩種方案中進行了實驗:第一種方案是採取連續座標並使用均方誤差損失;第二種方案是採取離散化座標並使用交叉熵損失。結果發現後者的效果更好。
期間,研究團隊通過爲每個座標(x、y)創建 7,000 個區間,來離散化太陽系中每個天體的位置向量,其中座標範圍爲-50 至 50 天文單位。需要說明的是,訓練期間他們使用 8 個英偉達 H100 GPU 進行了 25 個週期的訓練。
隨後,研究團隊在預留數據上針對模型預測結果進行評估,並發現預測效果較爲良好,其決定係數(R²)超過 0.9999,而且顯著優於基準模型,即優於那些總是預測最近位置或軌道均值的模型。與此同時,它還能以較高的精度生成長軌道。

(來源:https://arxiv.org/pdf/2507.06952)
Transformer 預測結果證明它是一個非常出色的序列模型。但是,它是否掌握了牛頓力學?爲了驗證這一點,研究團隊注意到,牛頓力學指出一系列軌道中的每次觀測都由一個狀態向量控制,該向量由每個行星的質量、相對速度和相對位置組成。鑑於軌道的下一個位置是確定的,所以如果基礎模型的歸納偏置依賴於牛頓力學,那麼它必須基於這個狀態向量進行外推。
研究中,研究團隊使用歸納偏差探針來評估模型的歸納偏差。他們創建了 100 個合成數據集,然後通過訓練模型來預測這些函數,從而對 Transformer 進行微調。其通過將 H 視爲恆等映射,並將損失函數 ℓ 設爲均方誤差,以便衡量模型在輸入上的外推預測能力,並通過將模型與一個基於狀態直接進行外推的“預言機”(oracle)進行對比來評估其中一個公式。
與此同時,他們將線性模型和雙層神經網絡作爲預言機,發現結果是相似的。其中,對牛頓狀態簡單函數的歸納偏倚較差。換言之,該模型的歸納偏置並不傾向於牛頓狀態。當它必須進行外推時,它會對狀態截然不同的軌道做出相似的預測,而對狀態非常相似的軌道則會做出不同的預測。
爲此,研究團隊通過創建一個序列到序列的數據集來對此進行測試,其中每個輸入是一條軌跡,每個輸出是“由軌道狀態所隱含的作用在行星上的”力向量。
基於此,他們先是針對預訓練的 Transformer 進行微調,使其能夠預測太陽系軌道上的力向量,並使用 1% 的真實力數據作爲訓練數據,結果顯示這些力預測結果不佳。
爲了評估該模型在掌握牛頓萬有引力定律方面的接近程度,研究團隊進一步對其進行微調,以便在包含 10,000 個太陽系的更大數據集上預測力的大小。
需要說明的是,符號迴歸是一種通過搜索優化迴歸類目標的符號表達式的方法。而當研究團隊將符號迴歸用於 Transformer 的預測結果時,得到的物理定律是毫無意義的。基準對比結果顯示:基於真實狀態訓練的 oracle 模型能夠精確預測力向量,符號迴歸則能完整復現真實的物理定律。

(來源:https://arxiv.org/pdf/2507.06952)

基礎模型並未習得某一通用物理定律
研究團隊表示,基礎模型的核心價值在於:序列預測能夠揭示對於潛在機制的深層理解。對於本次提出的評估框架來說,它通過分析模型在新任務遷移中的歸納偏差,來驗證模型是否習得預設世界模型。
實證結果表明,儘管許多序列模型在 next-token 預測任務中表現出色,但是它們對於真實世界模型的歸納偏置往往有限。本次研究還發現,這些模型並非是在學習連貫的世界模型,而是可能依賴了粗略的狀態表徵或非簡約的表徵。
總的來說,本次成果爲理解基礎模型的缺陷提供了一個方向:如果一個模型的歸納偏置並非傾向於某種已知的現實模型,那麼它傾向於什麼?
本次分析表明,這些模型實際上所表現出來的行爲,更像是開發了無法泛化的任務特定啓發式規則。在物理學領域,基礎模型並未習得某一通用物理定律,而是會根據所應用的任務採用不同的、看似毫無意義的定律。 目前,相關論文已被 2025 國際機器學習會議(ICML,International Conference on Machine Learning)收錄。
需要指出的是,本次研究需要指定一個世界模型,以此來測試基礎模型。世界模型需要明確定義的要求,雖與學界共識一致,但卻導致模型真實表徵機制的溯因分析存在固有侷限。儘管研究團隊提出了測試候選世界模型的策略(例如基於 next-token 分區的驗證方法),但未來研究應該優先開發“能夠自動構建基礎模型行爲中隱式世界模型”的技術。
參考資料:
https://arxiv.org/pdf/2507.06952
https://x.com/keyonV/status/1943730495264584079
https://x.com/keyonV/status/1943730486280331460
https://x.com/keyonV/status/1943730502948511937
運營/排版:何晨龍



