

機器人能否像人類一樣完成削黃瓜、擦花瓶等精細動作?要回答這個看似簡單的問題,需要深入分析其中的技術挑戰。
以削黃瓜爲例,這一操作需要削皮刀始終緊貼黃瓜表面並施加適當的力,對人類而言輕而易舉,但對機器人系統卻構成重大挑戰——亞毫米級的誤差就可能導致整個任務失敗。

(來源:arXiv)
當前機器人技術在這一領域面臨雙重困境:
首先,單一視覺模態的感知精度難以滿足需求,而引入觸覺/力覺等多模態信息又存在系統整合的根本性難題;其次,現有模仿學習算法雖然通過動作序列預測機制實現了平滑軌跡生成和減少累計誤差,但其開環控制特性將實際閉環控制頻率限制在1-2hz,這種滯後性嚴重阻礙了實時觸覺反饋的響應能力。
上海交通大學盧策吾教授團隊與清華大學許華哲助理教授團隊合作,通過多模態融合、提高閉環控制頻率與高質量數據採集的協同設計,創新性地解決了這一問題。他們的研究使機器人在接觸密集型任務的完成效果提升了 35% 以上,即使在人類干擾下也能完成削黃瓜、擦花瓶等傳統機器人難以完成的精細動作。
他們首先開發了新型觸覺數據採集系統 TactAR,通過 AR 技術提供實時處理的觸覺/力反饋。值得關注的是,TactAR 僅需一個成本爲 500 美元的消費級 VR 頭顯(Meta Quest3),這對於大規模推廣和應用具有重要意義。
在算法架構上,他們提出的 RDP(Reactive Diffusion Policy)算法融合了快慢雙網絡結構:首次使觸覺/力覺信號直接參與閉環控制,構建了“語義規劃-物理響應”的完整力覺控制鏈路。該算法既保留了擴散策略預測未來(例如 1 秒後)複雜動作序列的優勢,又在保持動作連續性的同時實現了接觸豐富任務中的快速響應,通過高頻閉環修正機制將控制頻率提升至數十赫茲。
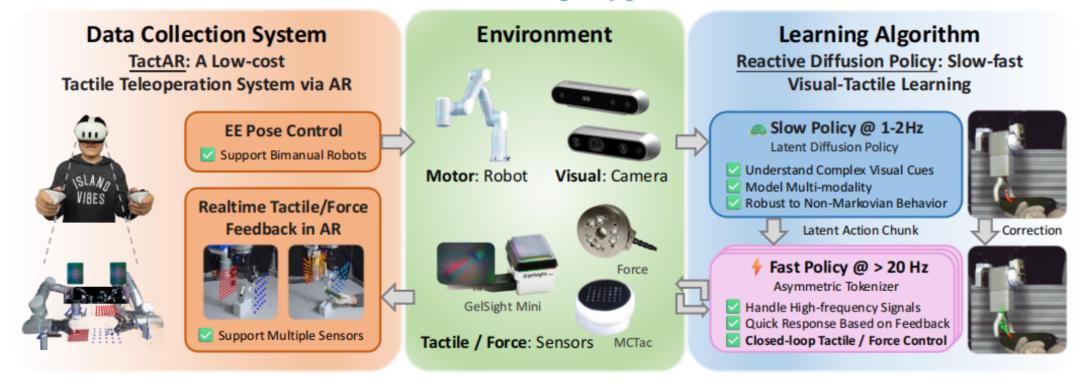
圖丨TactAR 系統和 RDP 算法(來源:arXiv)
實驗數據驗證了該系統的突破性性能。在動態干擾測試中,當人類操作者隨機下降、旋轉黃瓜或對花瓶製造突發擾動時,系統通過高頻率的觸覺/力覺反饋,展現出顯著的實時補償能力,將穩定維持操作位置及施加力的精度。這種將動作序列預測與實時反饋調整相結合的技術路徑,爲需要高精度人機協作的複雜操作場景提供了全新的解決方案範式。
審稿人之一對該研究評價稱:“該設計與經典的基於視覺的局部規劃器+快速阻抗控制器類似。從直觀上看,這種設計非常合理——局部觸覺信息用於生成高頻動作,而全局視覺輸入則用於制定短期未來的粗略規劃。”另一位審稿人則認爲,該研究對人類示範驅動的視覺-觸覺策略學習領域作出了重要貢獻。
日前,相關論文以《Reactive Diffusion Policy:面向接觸密集型操作的快慢視覺-觸覺策略學習》(Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation)爲題發表在預印本網站 arXiv[1],併入圍機器人頂會 RSS 2025(Robotics: Science and Systems)最佳學生論文提名。
來自上海交通大學的博士生薛寒、助理研究員任傑驥和博士生陳文迪是論文的共同第一作者,上海交通大學盧策吾教授和清華大學許華哲助理教授共同指導本項目。

圖丨相關論文(來源:https://reactive-diffusion-policy.github.io)

首次實現基於數據學習的觸覺/力覺信號閉環控制
該系統的設計受當前機器人研究領域現狀的啓發:依賴人工調參的傳統力控算法雖能實現精密操作(如柔性裝配、精密打磨),卻嚴重受限於場景特異性;而主流的視覺模仿學習方法雖具泛化性,但缺乏實時反饋能力,難以應對動態環境。
爲打破這種範式,研究團隊創新性地提出數據驅動的 RDP 快慢網絡架構,實現了力覺信息從高層規劃宏觀動作軌跡到低層執行高頻閉環微調的深度整合。
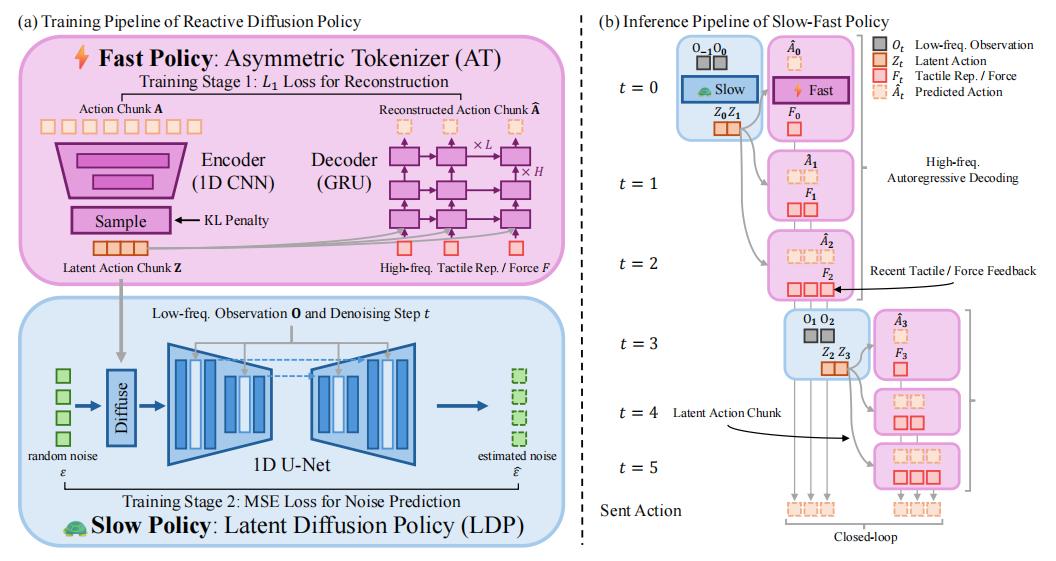
圖丨 RDP 框架概述(來源:arXiv)
快慢網絡神經架構 RDP 本質上是模仿人類雙手協同的操作模式——人類在執行任務時並非全程追求極高的精度,而是採用“快慢雙系統”策略:在接觸物體前,大腦會規劃一個粗略的運動軌跡和未來可能的反饋信號(慢系統);一旦產生接觸,小腦和肌肉系統立即接管,通過高頻觸覺反饋實時微調關節角度與肌肉張力(快系統),即使不用眼看也能完成精細抓取。
“這種雙層架構的設計既避免了人工參數調試繁瑣,又通過端到端學習自動適應了不同任務場景,爲通用觸覺/力覺-視覺操作機器人構建奠定基礎。”陳文迪對 DeepTech 表示。

圖丨陳文迪(來源:陳文迪)
RDP 算法將這一原理映射爲快慢雙網絡結構,這種架構本質上構建了“語義層-物理層”的分層控制:慢網絡處理語義穩定的長期規劃,如“沿黃瓜長度方向移動”;快網絡處理物理敏感的即時調整,如“接觸力超過閾值時回退 0.5mm”。兩個網絡各司其職又相互補充,最終實現了既有宏觀任務理解力,同時具備微觀物理適應性的機器人操作能力,爲複雜接觸任務提供了兼具魯棒性與精度的全新解決方案。
在性能驗證方面,RDP 系統在削皮、擦花瓶和雙臂搬運三項挑戰性任務中分別取得了 0.90、0.87 和 0.70 的平均任務完成效果,相較現有視覺模仿學習方法性能提升超過 35%,在精度、適應性和反應速度等方面均展現出顯著優勢。
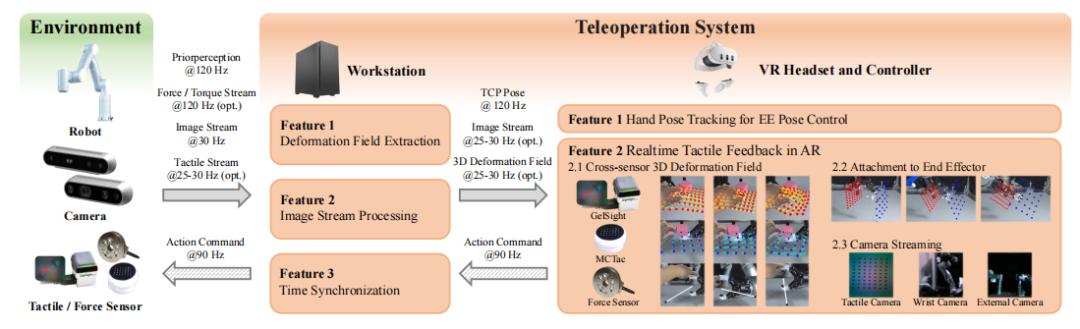
圖丨TactAR 操作系統概述(來源:arXiv)
這項研究充分體現了機器人領域研究的典型特點——系統層面的持續積累與硬件迭代的重要性。在系統搭建階段,研究團隊深入解決了硬件交互中的關鍵問題:從脆弱的傳感器保護到延遲補償,這些基礎工作爲後續研究奠定了堅實基礎。更重要的是,這套系統在後期的實驗中展現出巨大價值,不僅確保了高質量數據採集,更大幅提升了算法開發效率。
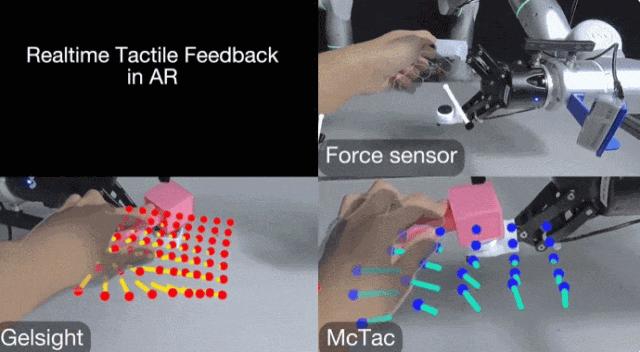
在算法開發階段,研究團隊意外地發現:原本爲視觸覺傳感器設計的策略,無需特殊調整就能完美適配噪聲特性完全不同的力傳感器。具體而言,RDP 算法在 GelSight Mini 觸覺傳感器、MC-Tac 觸覺陣列以及機器人內置關節扭矩傳感器等多種傳感模態上均表現出穩定的控制性能,這種跨傳感器的通用適配能力充分證明了該算法在硬件兼容性和系統魯棒性方面的突出優勢。

圖丨GelSight Mini 中不同接觸模式下標記變形場的示例(來源:arXiv)
陳文迪指出,“這一反直覺的現象揭示了我們的網絡架構和 RDP 設計具有出色的傳感器泛化能力——力傳感器的高頻噪聲未被特殊處理卻表現出最佳穩定性,這與傳統方法(如需要傅里葉變換或獨立處理)形成鮮明對比。”
這項成果不僅延續了盧策吾實驗室在力覺-視覺融合策略上的技術路線,更通過與清華大學許華哲團隊在觸覺學習方面的合作,驗證了高頻觸覺/力覺融合在靈巧操作中的潛力,爲後續構建通用多傳感器機器人模型奠定了基礎。

有望用於居家服務與柔性製造場景
隨着觸覺數據採集標準化的推進與算法迭代優化,該技術有望率先從家庭服務等高頻接觸場景落地應用,並逐步滲透至工業協作領域,最終實現“從生活到生產”的全場景覆蓋。
該系統在居家服務場景中展現出顯著優勢。研究團隊創新性的數據驅動 RDP 方法突破了傳統侷限,泛化的接觸式調節能力可以處理多樣化物體操作任務,無需針對每一任務人工設計規則,爲智能居家場景的通用化操作奠定了基礎。
再比如養老護理場景中,對人際交互安全性要求極高,而該系統的快速響應特性可爲未來機器人與人類實時互動提供了關鍵支持,有望提升服務可靠性和安全性。
(來源:arXiv)
在工業製造領域,該技術同樣展現出獨特的應用價值。當前傳統工業製造系統(如柔性製造線和食品加工產線)普遍面臨單一工件適配的生產瓶頸。相比之下,該技術呈現出顯著優勢:其數據驅動特性支持快速任務適應能力,同時系統具備的人機協作友好性爲製造業實現高效人機協同生產提供了創新解決方案。

圖丨三項實驗任務,包括削皮、擦花瓶和雙臂抬升(來源:arXiv)
爲實現技術的規模化應用,該團隊認爲,“提高硬件可靠性與算法性能”的協同發展路線非常重要:在部署環節,需要開發低成本且可靠的工業級傳感器,並充分發揮算法的抗噪能力來補償硬件精度的降低;在模型性能上,還需要進一步提高性能上限以滿足工業場景的需求。這種策略旨在顯著降低整體成本的同時提高可靠性,加速技術商業化進程。
在技術指標優化方面,他們確立了三個關鍵目標維度:首先將 RDP 系統的絕對成功率提升至 99.9%;其次提高其執行速度直至達到熟練工人水平;最後通過開發更具泛化能力的策略學習方法,減少數據需求並提升新任務適應能力,從而降低工業部署門檻。
未來可能的具體的技術升級將聚焦兩個核心組件:TactAR 數據採集裝置將通過一些更好用的觸覺/力覺反饋系統改進提升操作直觀性並進一步提高數據質量;RDP 控制算法將結合 VLA 框架擴展至多任務場景,並遷移至高自由度靈巧手平臺,以支持更復雜的應用任務。
基於現有研究框架,該團隊正重點攻關“力覺/觸覺驅動的複雜操作”這一核心方向,着力突破更有效的物理交互數據採集方案以及更通用的觸覺/力覺信號學習算法兩大關鍵技術。“這些技術突破將爲接觸密集型操作等傳統難題提供系統性解決方案,推動機器人操作技術向更高水平發展。”陳文迪說。
參考資料:
1.https://arxiv.org/abs/2503.02881
運營/排版:何晨龍



