春節假期還沒到,DeepSeek 就先把禮物拆了一半。
2 月 11 日,多位用戶發現 DeepSeek 的 App 端和網頁端已經悄然開始灰度測試一項重大升級:上下文窗口長度從此前 V3.1 版本的 128K token 直接拉到了 1M(百萬)token。DeepTech 驗證後確認,無論 App 還是網頁端,模型自述的上下文長度均爲“1M”。
與此同時,知識截止日期也從此前的版本更新到了 2025 年 5 月,在不聯網的情況下已經能夠準確回答 2025 年 4 月的新聞事件。不過,這個新版本目前仍然是一個純文本模型,不支持視覺輸入,也不具備多模態識別能力。

(來源:DeepTech)
以往 DeepSeek V3 系列僅 128K 的上下文容量是一個相當大的短板,本次提升至 1M 級別可謂進步巨大,此前,Google 的 Gemini 系列最先將上下文推至百萬級別。DeepSeek 此次直接對標 Gemini 的上下文長度,算是在這個維度上躋身第一梯隊。
值得注意的是,就在不到一個月前,DeepSeek 的 GitHub 倉庫 FlashMLA(其自研的多頭潛在注意力解碼核心庫)更新中,社區開發者發現了一個代號爲“Model 1”的神祕模型標識,它在 114 個文件中出現了 28 次,作爲獨立於當前 V3.2 架構的並行分支存在。
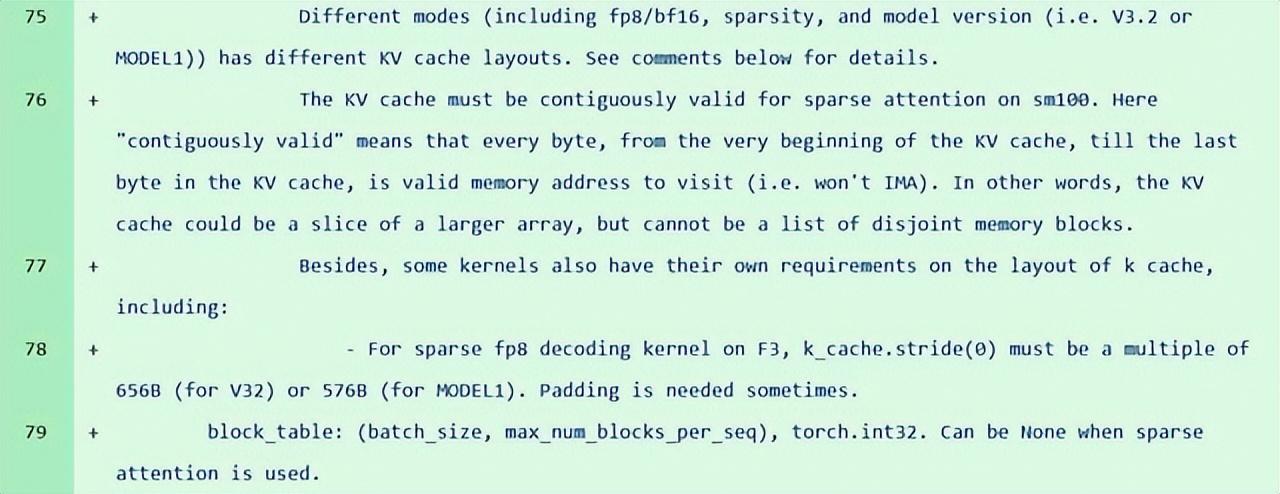
(來源:Github)
代碼層面的線索顯示,Model1 在 KV 緩存(Key-Value Cache)佈局、稀疏性處理和 FP8 數據格式解碼等方面與 V3.2 存在明顯差異,指向了一次架構層面的重大重構,而非簡單的版本迭代。這一發現恰好出現在 DeepSeek-R1 發佈一週年之際,更與此前媒體援引知情人士的報道,即 DeepSeek 計劃於 2 月中旬春節前後發佈下一代旗艦模型 V4 這一消息相呼應。
那麼,今天灰度測試的這個版本,是否就是傳說中 V4 的前奏?從技術邏輯上看,有一些拼圖已經擺上了桌面。過去一個多月裏,DeepSeek 以罕見的密度連續發佈了兩篇重要論文,創始人梁文鋒均署名參與。元旦當天發表的 mHC(Manifold-Constrained Hyper-Connections,流形約束超連接)解決了大規模模型訓練中的穩定性問題。
緊接着 1 月中旬開源的 Engram 模塊則提出了“條件記憶”(Conditional Memory)這一全新稀疏性維度,用 O(1) 複雜度的哈希查找取代昂貴的神經網絡計算來完成靜態知識檢索。Engram 論文中特別展示了將高達 100B 參數的嵌入表卸載到 CPU 內存、GPU 專注推理計算的能力,額外推理延遲低於 3%。
這種“查算分離”的架構天然適配超長上下文場景,當上下文窗口擴展到百萬級別時,傳統的全量注意力計算成本會急劇膨脹,而 Engram 結合去年 V3.2 中引入的 DSA(DeepSeek Sparse Attention)機制,理論上可以顯著降低長序列推理的計算開銷。
不過,灰度測試畢竟只是灰度測試,離正式發佈還有距離。目前尚不清楚這個版本的具體參數規模(據測試,其反應速度似乎要明顯快於 671B 的 V3 系列,有人猜測或爲 200B 模型)、是否已整合 Engram 和 mHC 等新架構組件,以及它在標準基準測試上的表現如何,這些信息 DeepSeek 均未披露。
去年 R1 在農曆新年前夕橫空出世,引發全球震動,英偉達市值單日蒸發 5930 億美元;而今年 DeepSeek 的故事還在慢慢展開。百萬 token 上下文的灰度測試可能只是小年夜的一道開胃菜。真正的年夜飯,或許還在後頭。
參考資料:
1.https://www.reddit.com/r/LocalLLaMA/comments/1qi06kp/one_of_the_deepseek_repositories_got_updated_with/
運營/排版:何晨龍