當所有智能體都在“少數服從多數”時,錯誤也可能被投票放大。但如果不再追求共識,會發生什麼?
一項研究結果顯示,僅通過單輪協作,無需達成共識,多智能體協同反而能實現更高的準確性、效率和魯棒性。
這個有些“反直覺”的結論,來自浙江清華長三角研究院信息技術研究所張海濱教授團隊(通訊作者)與北京理工大學團隊近期合作的研究,他們研發出一種多智能體協作架構 Free-MAD,打破了多智能體辯論必須“達成共識”的鐵律。
在多項任務評測中,Free-MAD 在顯著降低硬件資源需求的同時,無需達成共識,僅通過單輪協作,能高效組合數個(中小型)開源大模型,在部分複雜任務方面超越國際主流單體大參數模型(如 Gemini 3、GPT-5.2)的性能水平。

圖丨張海濱團隊(來源:受訪者)
近年來,多智能體協同正成爲提升大模型推理能力的熱門方向之一,Anthropic、月之暗面等機構也在關注該方向。
傳統方法中大模型特有的從衆機制是,哪怕是錯誤的觀點也要“少數服從多數”。另一方面,傳統多智能體協作方案通常需要兩至三輪交互才能達成共識,這會導致模型的準確率和性能均不高,並且費時費錢。
該方案摒棄了傳統方法,基於獎勵評分決策機制評估整個辯論軌跡,而非僅依賴最後一輪結果;同時通過抗從衆機制,使智能體有效識別並避免從衆錯誤推理的傳播。
與傳統方法相比,在該框架下僅需單輪多智能體交互,即可實現與傳統方法的推理相當的效果;在對抗環境下,具有更強的魯棒性、較低的推理開銷以及更高的可拓展性。
該研究爲在算力受限環境下實現高性能模型應用,提供了一種兼具成本和性能的技術路徑。對工業界而言,意味着可部署更輕量、更便宜、更安全的 AI 協作系統;對學術界而言,它開啓了“非共識化多智能體系統”的新方向。

圖丨相關論文(來源:arXiv)
參數堆砌之外的突破:多智能體協作的效率革命
當前,全球大模型技術發展呈現出明顯的結構性不平衡。一方面,國際上先進的大模型,例如谷歌的 Gemini、OpenAI 的 GPT 以及 Anthropic 的 Claude Opus 系列等仍以閉源爲主。儘管在性能和通用能力方面具有優勢,但受到技術封鎖、合規限制及地緣政治因素等影響,其難以實現廣泛獲取與使用。
另一方面,國內開源模型在透明性、可審計性和自主可控方面具備優勢,但不容忽視的一個問題是,其在綜合性能、複雜任務處理能力等關鍵指標上,與頂尖閉源模型仍存在一定的差距。
實際部署層面的挑戰同樣嚴峻,現有部分 200B 及以上參數規模的大模型(如 DeepSeek-V 系列、Qwen 高參數版本等)往往高度依賴多張 NVIDIA H200 級 GPU 硬件,單卡成本較高,這對整體算力來說是一項較高的支出。
相比之下,輕量級小參數模型,例如 32B 級開源模型可在多張 NVIDIA 4090 級別的消費級顯卡環境下完成部署,但它的侷限性在於單模型能力在複雜任務場景和應用深度方面受限。

圖丨基於分數的 Free-MAD 協議及其評價(來源:arXiv)
在此背景下,研究團隊開發了全新多智能體協作架構 Free-MAD。爲有力抑制答案的“盲目跟風”,研究人員引入了反從衆的機制來重構辯論階段。通過鼓勵批判性思維,系統可實現主動降低對多數意見的敏感度。
張海濱對 DeepTech 解釋道:“不能爲了達成共識而達成共識,而是應該去思考問題的本身。每個大模型或智能體都會產生自己的思考結果,其不僅要收到對方的結果來做決定,更重要的是,要用批判性思維來看待對方的推理過程是否合理。”
在決策階段,研究團隊基於純算法邏輯引入了獎勵評分決策機制,來評估整個辯論軌跡。這樣,最終決策並非取決於最後一輪“誰聲量高聽誰的”,而是通過全程追蹤辯論過程中所有智能體的每次推理軌跡變化。
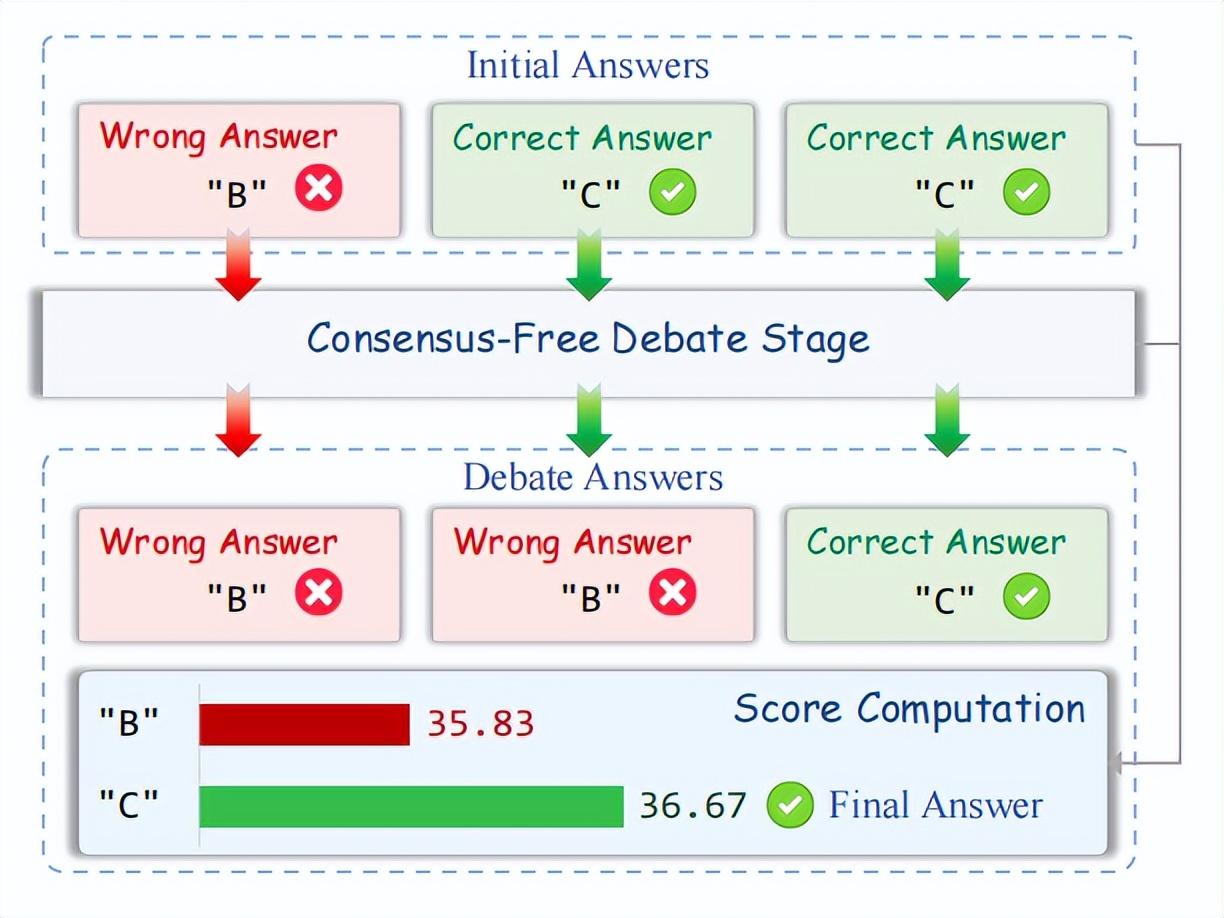
(來源:arXiv)
這種決策邏輯帶來的好處是,無需在辯論階段達成共識,即便正確答案在末輪未獲得多數投票,系統仍可能基於它在辯論過程中的穩定表現或合理轉變而獲得結論。
除了開發全新的推理框架,這項研究還揭示了多智能體協同中有趣的現象:有的場景下,異構模型的效果強於同構模型;但其他場景下,同構模型反而更強,甚至對應不同的工作或者任務,需要動態調整核心算法與參數。
對於非專業的用戶來說,Free-MAD 無異於通用大模型或智能體應用,而針對專業用戶,研究團隊在此基礎上進行參數調優,進化出高度優化的通用版本 MAX-MAD,使性能和準確率進一步提升,以應對不同的場景和賽道。
“參數調優的好壞直接關係到準確性,甚至關係到整個共識達成的速度。因此,我們設置了額外的一些重要的參數調優。”該論文第一作者崔宇對 DeepTech 表示。
據悉,該系統前置了三個重要模塊:針對輸入任務的分類(例如數學、推理、哲學,或其他問題)等,對任務複雜度評估以及策略參數優化器。此外,研究人員還開發了智能體的自適應模塊以及反饋機制的收集。
破解大模型協作中的從衆難題
在實驗部分,研究團隊的測試覆蓋了 8 個數據集,包括數學推理(GSM-Ranges、AIME2024、AIME2025 和 MATH500)、邏輯推理(StrategyQA 和 MMLU 的邏輯謬誤數據集)、知識和理論推理(AICrypto 的多選題數據集)等。
據團隊介紹,在綜合數學推理測試中,研究人員綜合使用國內的四大開源模型組合(Qwen3-235B、DeepSeek-V3.2、Kimi-K2 和 GLM-4.7)以及調用同一個國產大模型的單一組合(以上任意一種大模型, 如 Qwen3-235B)。
綜合來看,Free-MAD 和 MAX-MAD 通過多智能辯論後,能夠達到約 86.67%-90% 的準確率,不僅將四個單體模型本身的準確率大幅提升了 15-30%,更值得關注的是,該準確率也超過了主流閉源模型(如 Gemini 3、GPT-5.2)在相同數據集上的公開成績。
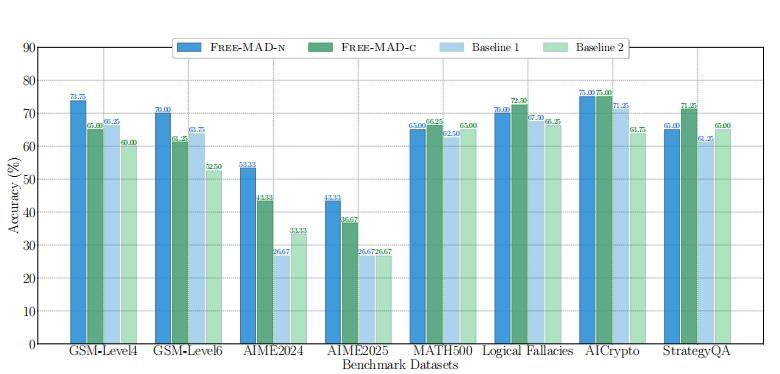
(來源:arXiv)
基線方法採用了被廣泛採用的多智能體辯論框架 SoM,結果顯示,Free-MAD-N(反從衆辯論+評分決策)在單輪辯論(R=1)時準確率達 64.43%,比基線 2 高近 10%,比基線 1 高近 19%。
值得關注的是,基線方法在單輪辯論時效果不佳,單輪無法形成共識;而 Free-MAD 不需要共識,單輪結果優於基線兩輪成績。
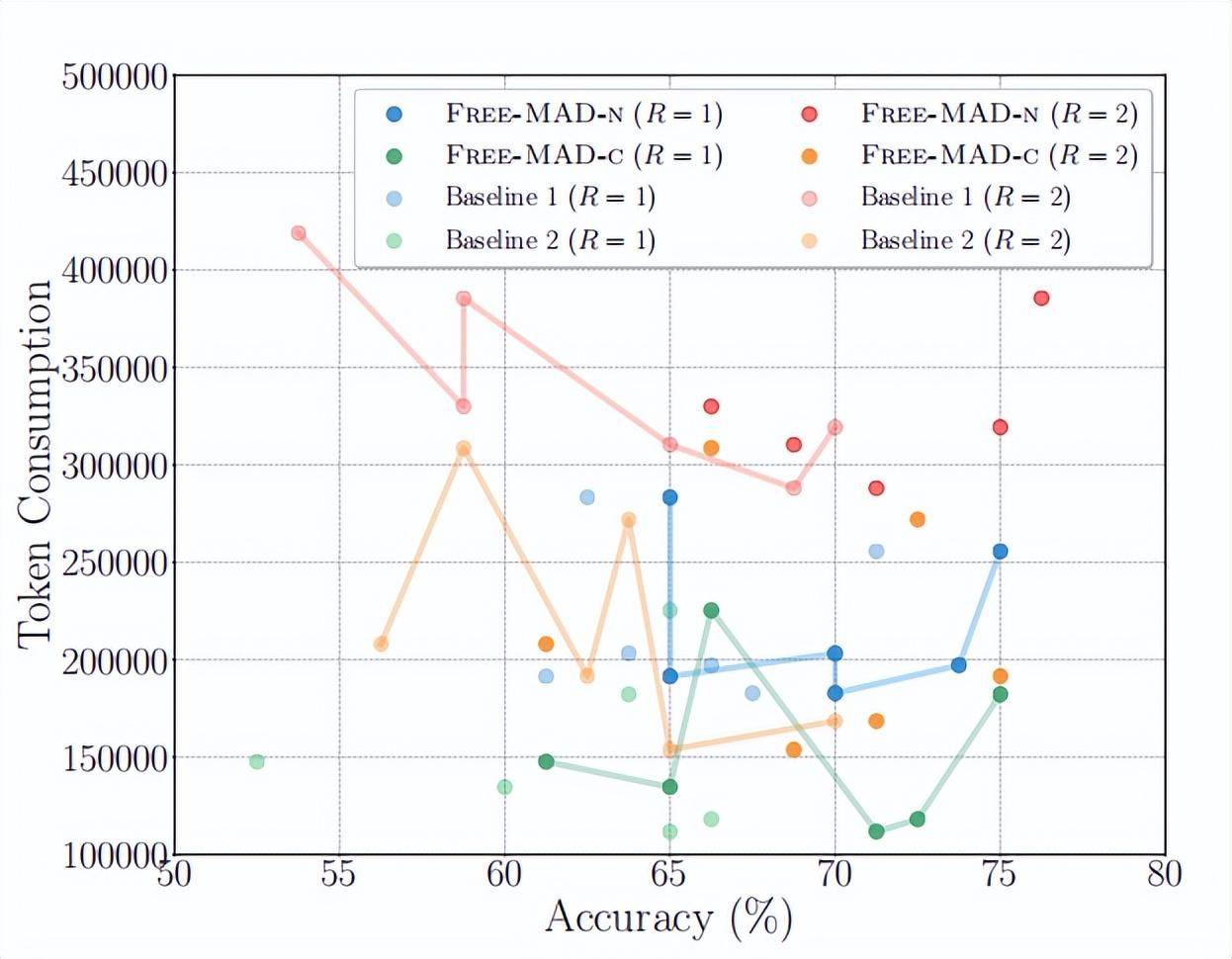
圖丨在不同辯論輪次下,比較 Free-MAD 方案與基線方案在 token 消耗和推理準確度方面的差異(來源:arXiv)
從 token 消耗結果來看,Free-MAD 或 MAX-MAD 的輪數由原來的兩三輪變成現在的單輪,相當於整個 token 的使用量或帶寬的使用量降爲原來的一半。“這也是一項重要的成本節省。”張海濱說道。
在安全性方面,研究團隊也進行了相關設計。智能體往往涉及到多智能體協作,50% 智能體被斷網時,基線準確率會下降 15%-20%。因此,需要考慮的情況是:萬一部分智能體無法正常工作,或系統的一部分不工作的情況,是否能保障系統的安全性,以及是否仍能夠按時獲得輸出結果。
經過研究人員測算,Free-MAD 或 MAX-MAD 系統在抵禦宕機或通信攻擊情況下的表現較爲理想。實驗結果顯示,即便智能體(短暫)離線,或受到敵手攻擊,不能把自己的信息發送情況下,其餘的智能體也能準確地完成任務。
從實驗室走向產業:多智能體協作的落地路徑
據研究團隊介紹,來自研究社區的英國獨立研究團隊已基於該成果復現了 Free-MAD。值得注意的是,相關團隊將包括權重在內的所有系統超參數設爲自適應可配置,並引入了基於歸一化的方法及若干額外工程化策略,顯著提升了系統的實用性與並行能力。
這種兼具安全性和性能優勢的框架有望用於高質量推理內容生成,以及智慧醫療、輿情治理、金融分析等高安全敏感應用領域。
在高質量內容生成領域,基於框架較強的通用性,該方案可直接用於任意大模型和智能體進行傳統的智能問答。儘管它在結果返還速度上相對傳統大模型較慢,但基於辯論優化邏輯鏈,可大幅度提升政策解讀、行業報告等文本的專業性與可信度。
在智慧醫療領域,該成果有望模擬心內、影像、病理等多科室專家會診,甚至產生辯論,來對疑難病症進行診斷。
例如,三個智能體分別對患者病情進行評估,在其中兩個智能體誤判爲良性,一個智能體堅持是惡性的情況下,傳統的 MAD 方法有可能因爲共識壓力輸出錯誤的結果,而該方案能通過特有的軌跡分析,識別出少數派的紮實推理理念,進而做出更精準的評估。
在輿情治理方面,可構建虛擬的辯論社區,多角度解構輿情領域的脈絡,實現風險的早識別、早干預。目前,在汽車輿情的治理方面,研究團隊已經有相關落地案例。張海濱指出,“從結果來看,通過辯論得到的結果,明顯優於單模型或傳統共識型多智能體方案。”
在金融分析領域,多 Agent 協同有利於更好地研判市場信號,生成邏輯嚴密的投資策略和風控報告。
圖丨張海濱(來源:受訪者)
張海濱教授目前擔任浙江清華長三角研究院信息技術研究所所長、學術帶頭人,其團隊致力於爲 AI 提供從數據層、模型層到應用層的完善解決方案。
該團隊承擔多項國家級與省部級科研項目,例如“天樞·可信數據空間”。圍繞可信數據空間與多智能體協同架構展開研究,並落地大小模型協同的“天跡·工業智能體”。相關成果已在能源、電信、國家電網、國家管網等領域落地,並參與包括央行數字貨幣等在內的多邊金融基礎設施項目建設。
在未來的研究中,該團隊計劃構建新一代策略參數優化的更高性能、更準確的多智能體協作框架。目前,他們正在探索將該框架與硬件系統結合的可能性,旨在通過硬件優化解決多智能體辯論中分詞、解碼及廣播帶來的帶寬消耗和延遲問題。
在算力成爲瓶頸的時代,或許這類架構創新比單純堆參數更具戰略意義。
參考資料:
1.Yu Cui, Hang Fu, Haibin Zhang, Licheng Wang, Cong Zuo, Free-MAD: Consensus-free multi-agent debate, arXiv preprint arXiv:2509.11035
2.系統已開放內測,感興趣的讀者可郵件聯繫李老師: [email protected]
運營/排版:何晨龍