1970 年,數學家約翰·康威發明了“生命遊戲”(Game of Life)。在一塊無限延伸的棋盤上,每個方格非生即死,遵循幾條極其簡單的規則:活細胞如果鄰居太少就會孤獨而死,太多則因擁擠而亡;死細胞恰好有三個活鄰居就會復活。
沒有人下棋,沒有人操控,但這些簡單規則跑起來之後,屏幕上會湧現出滑翔機、脈衝槍、甚至可以模擬圖靈機的複雜結構。半個多世紀以來,這個實驗一直被視爲複雜性科學的經典演示,展示簡單規則如何生成無窮複雜的行爲。

圖丨康威的“生命遊戲”(來源:WikiPedia)
沒人想過這些東西能教 AI 說話。直到現在。
MIT Improbable AI 實驗室 Pulkit Agrawal 團隊在今年 3 月發表了一篇論文,提出了一個聽起來相當不合常理的想法:用類似“生命遊戲”的細胞自動機生成的數據,去預訓練大型語言模型。這些數據不包含任何文字、任何語義,只是一個 12×12 網格上像素不斷演化的軌跡。

圖丨Pulkit Agrawal(來源:MIT CSAIL)
但實驗結果顯示,在這些純粹的“動態圖案”上訓練過的模型,在隨後的自然語言學習中表現得更好,困惑度(perplexity)降低了最多 6%,收斂速度加快了最多 1.6 倍。更讓人意外的是,僅用 1.64 億個細胞自動機 token 做預訓練,效果竟然超過了用 16 億個真實英語文本(來自 Common Crawl 數據集 C4)做同樣的預訓練。
這項工作的核心思路可以用一句話概括:語言模型真正需要學習的,可能不是語言本身,而是語言背後的計算結構。
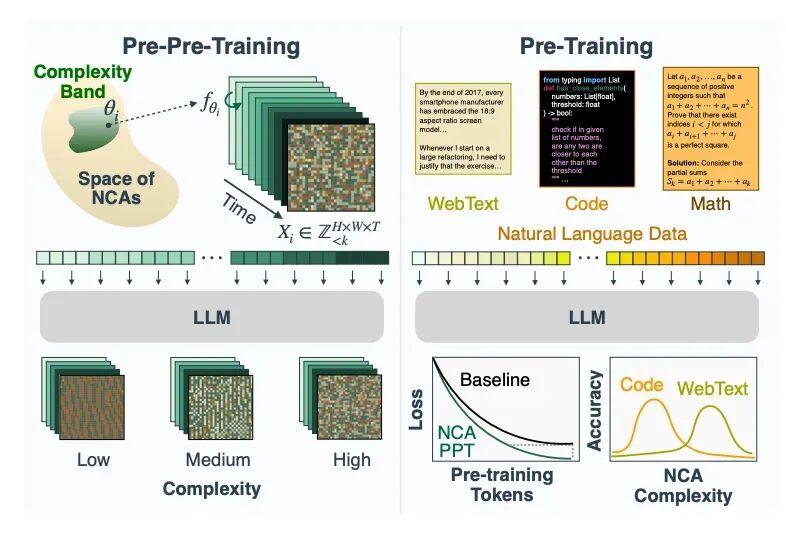
圖丨NCA 預預訓練到語言預訓練的概覽(來源:arXiv)
研究團隊使用的是“神經細胞自動機”(Neural Cellular Automata, NCA),這是經典細胞自動機的一種推廣。傳統的細胞自動機(比如康威的生命遊戲)使用固定的規則,而 NCA 把規則替換成了一個小型神經網絡,具體來說是一個 3×3 卷積加上一層 MLP。
每次生成訓練數據時,研究者隨機初始化這個網絡的權重,等於隨機抽取一條全新的動力學規則,然後讓它在網格上跑出一段時空演化軌跡。這些軌跡被切割成 2×2 的圖像塊,映射爲 token 序列,再用標準的下一個 token 預測任務來訓練 transformer。
換句話說,模型拿到的每一條序列,都來自一個它從未見過的規則。要預測下一個 token,它必須在上下文中推斷出這條隱藏規則,然後應用它。這和語言模型在真實文本上做的事情存在某種深層對應。
斯坦福大學馬騰宇與 Percy Liang 團隊在 2022 年的工作中就曾論證,下一個 token 預測本質上是一種隱式的貝葉斯推斷:模型從已有的文本中推斷出潛在的“生成概念”,再據此預測接下來會出現什麼。NCA 訓練把這個過程提純了。自然語言中混雜着語義快捷方式和共現先驗,模型可以“投機取巧”;而 NCA 數據中沒有任何語義可以依賴,每一個 token 都在迫使模型做純粹的規則推斷。
這套方法被稱爲“pre-pre-training”,即在正式的語言預訓練之前,先用合成數據做一輪“預預訓練”。
訓練流程分三步走:先在 NCA 數據上訓練 transformer 的非嵌入層權重,再在自然語言語料(網頁文本、代碼或數學文本)上做標準預訓練,最後是針對具體任務的微調。研究者測試了三個下游語料庫,分別是 OpenWebText(網頁文本,約 90 億 token)、OpenWebMath(數學文本,約 40 億 token)和 CodeParrot(代碼,約 130 億 token),在所有三個領域上都觀察到了持續的改善。
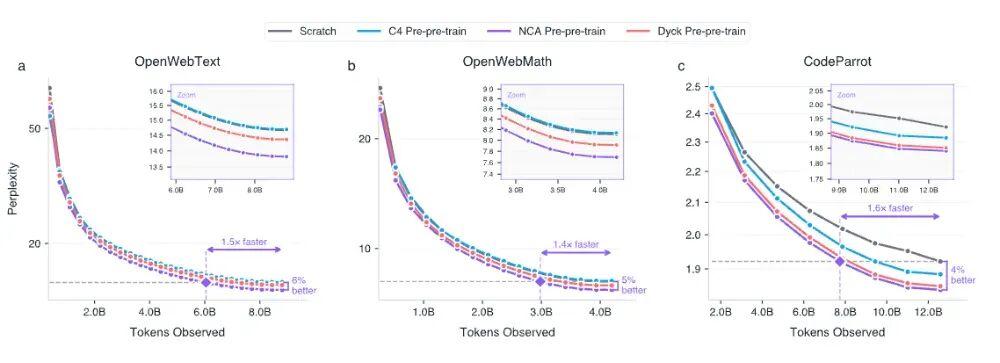
圖丨NCA 預預訓練在多個領域改進並加速了語言模型預訓練(來源:arXiv)
在推理基準測試上,收益同樣可見。GSM8K 數學推理測試中,NCA 預訓練將 pass@1 從 3.8% 提升到 4.4%;HumanEval 代碼生成測試中,pass@1 從 6.8% 提升到 7.5%;BigBench-Lite 綜合推理測試中,pass@4 從 25.9% 躍升至 36.5%。
絕對數字不算大,這些畢竟是 16 億參數的模型,而非千億級的商用系統,但對照實驗的一致性指向了一個清晰的信號:從非語言數據中習得的某些東西,確實在幫助模型處理語言任務。
那麼,到底是什麼被轉移了?研究者做了一個拆解實驗:在 NCA 預訓練完成後,選擇性地重新初始化模型的不同組件(注意力層、MLP 層、LayerNorm 層),然後觀察下游表現的變化。結果非常明確:重新初始化注意力權重造成的性能損失最大,遠超其他組件。這意味着注意力層承載了最多的可遷移結構。
MLP 層的效果則因領域而異:在 OpenWebText 上,保留 NCA 階段的 MLP 權重反而會干擾語言學習;但在 CodeParrot 上,影響可以忽略不計。
這一發現和最近 Jelassi 等人(2025 年)對混合專家(MoE)架構的分析形成了一定程度的呼應,那項工作表明擴大 MLP 參數主要增強的是記憶能力而非推理能力。兩相對照,一幅功能分工的圖景浮現出來:注意力層負責學習通用的依賴追蹤和上下文推斷機制,MLP 層則傾向於存儲特定領域的模式和統計規律。正因如此,注意力層從 NCA 到語言的遷移是“萬金油”式的,而 MLP 的遷移效果取決於源域和目標域之間的匹配程度。
研究中另一個值得關注的發現有關於複雜性匹配。團隊使用 gzip 壓縮率作爲 NCA 軌跡複雜性的度量,壓縮率低意味着數據更有規律、更可預測,壓縮率高則意味着更豐富的時空結構。他們把 NCA 數據按壓縮率分成幾個區間(20-30%、30-40%、40-50%、50% 以上),分別測試各區間對不同下游領域的遷移效果。
結果表明,網頁文本和數學文本從高複雜度 NCA(50%+ 壓縮率)中受益最大,而代碼領域的最優區間在中等複雜度(30-40%)。有意思的是,這恰好與目標語料自身的複雜度特徵對齊,OpenWebText 和 OpenWebMath 的 gzip 壓縮率在 60-70%,CodeParrot 則只有 32%。
這意味着,合成數據不是“越多越好”或“越複雜越好”,而是需要與目標領域的計算特徵相匹配。研究者稱之爲“domain-targeted data design”,一種自然語言訓練中不存在的調控槓桿。你無法輕易改變英語的統計特性,但你可以調整 NCA 的規則空間、字母表大小、複雜度分佈,讓它精確匹配你想要訓練的能力。
這項工作的理論背景可以追溯到幾條學術脈絡。一條是 MIT 同校 Phillip Isola 團隊在 2024 年提出的“柏拉圖表徵假說”(Platonic Representation Hypothesis),核心觀點是不同模態、不同架構的 AI 模型,隨着規模增大,內部表徵正在趨同,彷彿都在逼近對現實世界的某種共同的統計模型。如果這個假說成立,那麼從非語言數據中能學到與語言相通的表徵,就不那麼令人驚訝了。
另一條脈絡來自 Finzi 等人(2026 年)提出的“epiplexity”概念,它指出對於計算能力有限的觀察者而言,簡單的確定性過程也能生成需要學習才能把握的結構信息。經典信息論認爲確定性變換不能增加信息量,但那假設的是全知全能的觀察者;對於一個有限容量的 transformer 來說,生命遊戲中湧現的滑翔機和碰撞圖案,確實包含了它必須“理解”才能預測的東西。
關於“爲什麼 1.6 億 token 的自動機數據能勝過 16 億 token 的英語”,研究者給出的解釋是:在遠低於計算最優規模的 token 預算下(Chinchilla 定律建議 16 億參數模型需要約 320 億 token),自然語言訓練主要在學習淺層的局部模式,比如詞彙搭配、句法片段這些“表面功夫”。
而 NCA 數據由於每條序列都對應一個獨特的動力學規則,多樣性極高,冗餘性極低,每個 token 都在訓練模型做深層的規則推斷。加之 Abbas 等人(2023 年)的研究已經表明大規模自然語言數據集內部存在大量語義冗餘,NCA 在 token 效率上的優勢就變得可以理解了。
不過,目前這個實驗的規模還限於 16 億參數,距離工業級的千億參數模型還有數量級的差距。NCA 預訓練的增益隨模型規模增大而遞減,400M 模型改善了 8.6%,1.6B 模型改善了 5.7%,這個趨勢在更大規模上是否會完全消失,目前還不清楚。
此外,對於較大字母表(n=10, 15)的 NCA,收益在一定 token 預算後出現飽和甚至下降,說明簡單地“生成更多 NCA 數據”並不是萬能解法。如何從理論上指導合成數據的生成,使其精確匹配目標領域的計算特徵,仍然是一個開放的研究問題。
但研究者們的期望不止於此。論文的結尾寫道,他們的最終願景是完全用乾淨的合成數據做預訓練,只在最後階段用少量經過精心篩選的自然語言來獲取語義。當前的“預預訓練”框架是這個範式的早期原型。
參考資料:
1.https://arxiv.org/pdf/2603.10055
運營/排版:何晨龍