近年來,隨着多模態大語言模型(MLLM)的快速發展,研究者們開始嘗試將其應用於通用多模態檢索任務。與此同時,思維鏈(Chain-of-Thought,CoT)推理被引入檢索領域,通過增強模型的推理能力來改善候選結果的排序。
然而,一個重要問題始終未能得到解決:現有的推理過程本質上仍然是語言驅動的,模型無法在推理過程中主動獲取和驗證視覺細節,因此在面對相似的候選圖片時容易“瞎猜”。
近日,清華大學聯合、復旦大學、香港大學等機構,推出了首個基於“Interleaved Reasoning”的通用多模態檢索框架 V-Retrver。該框架將傳統檢索重塑爲智能體推理過程,讓多模態大模型學會在檢索時主動調用視覺工具來驗證細節,而非僅憑靜態的圖像表徵進行判斷。目前,研究團隊已將代碼和模型權重開源。

(來源:arXiv)
“從 2025 年初開始,推理模型開始火起來,很多工作把推理模型用在下游任務,多模態檢索就是其中之一。”團隊成員向 DeepTech 表示,“但現在這些推理模型的 CoT 過程是從文本推理的。問題在於,多模態檢索的輸入是多張圖像,你要從十張候選圖片中找到最相關的那張,僅靠文本推理會產生幻覺。”
這種侷限在視覺模糊的檢索場景中尤爲明顯。尤其當候選圖片在語義上高度相似,僅在細節上存在差異時。比如同樣是白色沙發,只是抱枕紋理不同,模型往往無法準確區分。傳統方法將視覺輸入壓縮成固定的特徵向量或文本描述,迫使推理過程完全依賴語言來推斷視覺差異,結果就是模型只能瞎猜。

(來源:論文)
更關鍵的是,現有模型看圖是“一次性”的。用了一個形象的比喻:“傳統模型看完圖就憑印象做題,面對複雜的圖文交錯檢索,它們無法在推理遇到瓶頸時主動去驗證視覺細節。”這種走馬觀花式的視覺處理方式,導致模型在需要精細判斷時表現不佳。
讓模型學會“放大找細節”
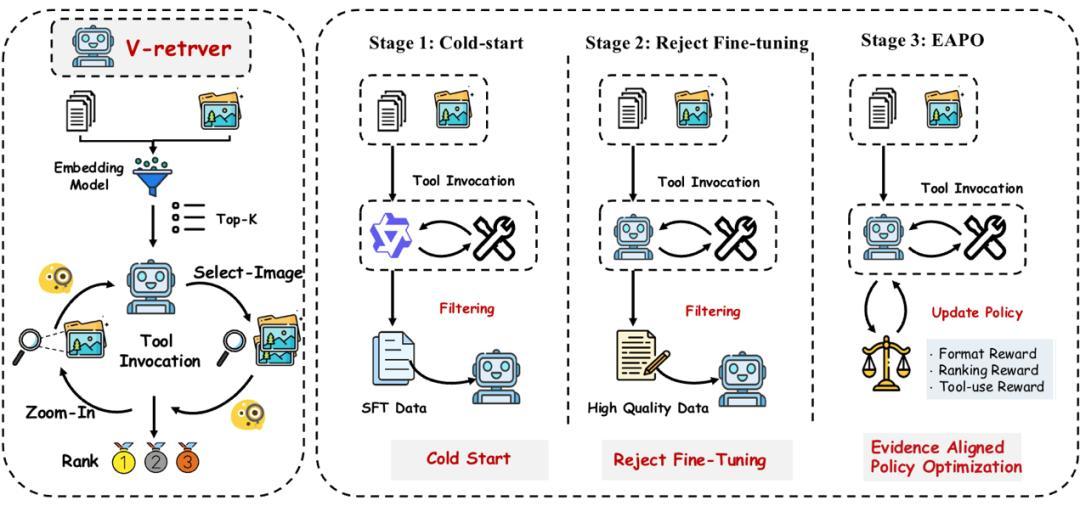
V-Retrver 的核心理念是將多模態檢索重新定義爲一個“多模態思維鏈的推理過程”。與傳統的單次推理不同,模型在推理過程中可以主動調用外部視覺工具來獲取更多信息,就像人在看不清某個細節時會把圖片放大仔細看一樣。
團隊表示,這是首個將交錯推理(Interleaved Reasoning)應用於多模態圖像檢索的工作。此前的相關研究主要集中在簡單的圖像理解和視頻理解任務上,例如單圖問答場景。
論文作者之一以一個具體場景說明了這一過程:“假設輸入是一段文字描述,需要從 10 張候選圖片中找到最相關的一張。模型在分析過程中,如果發現某張圖片的關鍵細節看不清楚,就會調用工具對該區域進行局部放大後再做判斷。比如查詢文本提到‘桌上放着某個物品’,而這個物品在圖像中位置較小、較模糊,模型就需要放大查看才能做出準確判斷。”
這種“邊看邊想”的過程與人類的認知方式很像,當我們在網購時遇到相似的商品,也會點開大圖看買家秀細節來做出對比和判斷。
這種“產生疑問→調取工具覈實→得出結論”的邏輯閉環,正是 V-Retrver 區別於傳統方法的關鍵所在。
三階段訓練:從“學會用工具”到“聰明地用工具”
讓模型學會何時以及如何使用這些視覺工具,並非易事。V-Retrver 採用了三階段的課程學習策略。
第一階段是監督微調(SFT),目標是教會模型基本的工具調用能力。“我們使用 LLM 來合成訓練數據,這批數據包含了檢索過程中調用工具的示例,讓模型學會何時以及如何調用工具。”作者表示,這個階段的數據質量至關重要,也是整個訓練過程中最具挑戰性的環節之一。
SFT 階段的訓練量需要精心控制。作者指出,這裏存在兩個極端:訓練過度會導致模型在強化學習階段過度依賴工具,對每個樣本都嘗試調用;訓練不足則會使模型無法掌握工具調用能力。
第二階段是拒絕採樣微調(RSFT),通過篩選高質量的推理軌跡來提升模型的推理可靠性和格式合規性,爲後續的強化學習提供穩定的初始化。
第三階段是證據對齊策略優化(EAPO),這是基於 GRPO 算法的強化學習過程。“我們設計了一個工具調用獎勵機制,”作者解釋道,“當模型在推理過程中合理調用工具時會獲得正向獎勵。我們希望模型能夠適度使用工具進行驗證,而非完全不用或過度依賴。”
(來源:論文)
經過強化學習訓練後,模型能夠實現自適應的工具調用。有些問題需要調用工具來驗證細節,有些則不需要,模型會自主判斷。
性能提升顯著,泛化能力突出
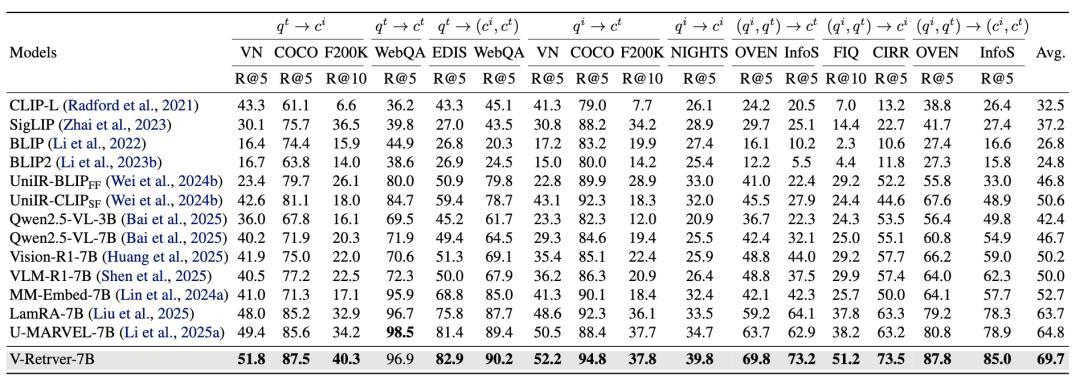
在通用多模態檢索基準 M-BEIR 上,V-Retrver-7B 取得了 69.7% 的平均召回率,相比此前最強的 U-MARVEL-7B 提升了近 5 個百分點,相對基礎的 Qwen2.5-VL-7B 模型則提升了 23%。
(來源:論文)
值得注意的是,V-Retrver 在需要精細視覺判斷的任務上表現尤爲突出。在 FashionIQ 數據集上達到 51.2%,在 CIRR 數據集上達到 73.5%,分別比 U-MARVEL-7B 高出 13 個和 10 個百分點。這驗證了多模態交錯推理在處理細粒度視覺差異時的有效性。
在零樣本泛化測試中,V-Retrver 同樣表現優異。在從未見過的 CIRCO 數據集上取得了 48.2 的 MAP@5 成績,顯著超過 MM-Embed-7B 等專業檢索模型。
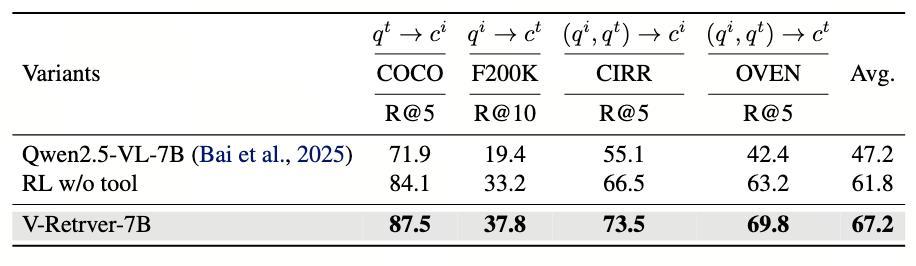
消融實驗進一步證實了視覺工具的價值:如果剝奪 V-Retrver 的視覺工具,只讓它做純文本的 CoT 推理,平均性能會從 67.2% 跌至 61.8%。
(來源:論文)
團隊在論文中也坦誠地表明瞭當前工作的侷限性。最明顯的是推理成本問題:相比傳統的 embedding 方法,V-Retrver 需要更多的計算資源和時間。“我們在這個工作中沒有專門做權衡,這確實是一個問題,也是後續可以繼續研究的方向。”
另一個侷限是視覺工具的種類相對有限,目前只有 ZOOM-IN 和 SELECT-IMAGE 兩種。研究團隊計劃在後續工作中引入更多類型的工具,其中包括網絡搜索工具。
作者以一個例子說明了引入 web search 工具的潛在價值:假設檢索目標是“穿着黃色衣服的拿破崙”,但候選圖片中存在其他穿着相似服裝且外貌接近的人物,僅憑服裝顏色難以區分。此時模型可以通過網絡搜索獲取拿破崙的其他標誌性特徵,並將這些信息作爲輔助依據,提升檢索的準確性。
V-Retrver 的出現,標誌着多模態檢索研究從“靜態編碼 + 語言推理”向“動態感知 + 交錯推理”的範式轉變。它證明了一個樸素而重要的道理:在處理視覺任務時,模型不僅需要“想”,更需要“看”。而且要學會在需要的時候主動去“仔細看”。
參考資料
1.論文鏈接:
https://arxiv.org/abs/2602.06034
2.項目地址:
https://github.com/chendy25/V-Retrver
運營/排版:何晨龍