

多年來,美國伊利諾伊大學香檳分校博士畢業生、Keiji.AI 公司聯合創始人王子豐一直在研究將 AI 應用於臨牀試驗,並已開展多個相關項目,包括開發用於臨牀試驗系統評價的輔助工具 TrialMind [1] 和 LEADS [2],提升試驗招募效率的 TrialGPT [3],支持生物醫學數據分析的智能平臺 DSWizard [4,5],以及自動生成臨牀試驗文檔的系統 InformGen [6]。

圖 | 王子豐(來源:王子豐)
在推進這些研究的過程中,王子豐逐漸意識到,儘管製藥業內對 AI 在臨牀試驗中的應用充滿期待,但仍面臨諸多關鍵挑戰。
首先,目前缺乏有效的評估手段,使得大模型難以在臨牀試驗場景中實現可驗證、可落地的應用。
其次,真正理解制藥行業實踐的專業人士與 AI 技術專家之間存在明顯的知識壁壘,跨領域協同不足,也限制了技術轉化的深度和廣度。
而在構建垂直領域模型和 Agent 的過程中,人們又面臨着兩個根本性的問題:一是缺乏結構清晰、適合 AI 訓練的高質量數據資源,二是缺乏貼近真實臨牀試驗任務、能夠系統評估模型能力的基準任務集。
業界其實有一些出售臨牀試驗商業數據的公司比如 Citeline,但是這些數據都非常昂貴,一般大型的製藥企業可能每年向他們支付數百萬美元以上來獲取這些信息。而公共數據比如 ClinicalTrials.gov 只包括了在美國註冊的試驗記錄,而很多的多個國家試驗記錄以及發表的試驗都需要被額外收集和標準化處理。
基於上述問題,王子豐等人啓動了本項研究,構建了臨牀試驗領域的大規模結構化數據庫 TrialPanorama [7],匯聚了試驗設計、干預手段、適應症、生物標誌物、結局指標等核心要素,並對接權威醫學本體,確保數據的一致性與可擴展性。在此基礎上,研究團隊進一步設計了一套配套的評測任務集,涵蓋從文獻評價到試驗設計的多個關鍵環節,以用於系統性地評估 AI 模型在臨牀試驗相關任務中的能力。該工作不僅爲模型的訓練與測試提供了高質量數據支撐,也爲後續開發 AI Agent 提供數據源。
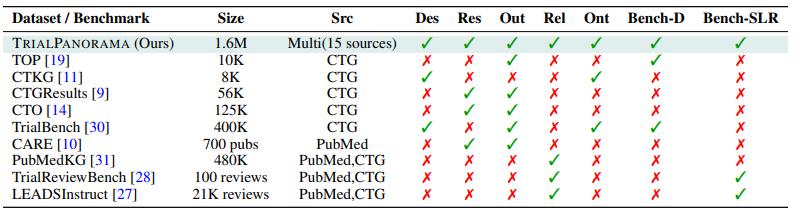
如前所述,本次研究的主要成果是構建了一個覆蓋廣泛、結構清晰的臨牀試驗數據庫 TrialPanorama,共收錄了來自全球 15 個來源的 1,657,476 條臨牀試驗記錄以及彙總這些臨牀試驗的超過 9,000 篇系統評價論文。該數據庫系統性地整理了臨牀試驗設計與實施的關鍵要素,包括研究方案、干預方式、適應症、生物標誌物和結局指標等,並與標準醫學本體(如 DrugBank 和 MedDRA)進行了對齊,具備良好的規範性與可擴展性。
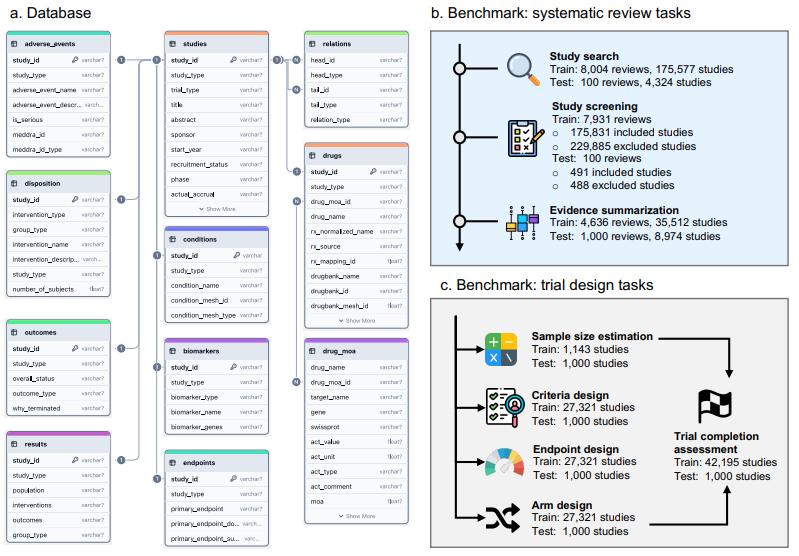
在此基礎上,研究團隊還首次設計併發布了一套面向臨牀試驗任務的大模型評測基準,涵蓋系統評價和試驗設計累計兩個類別和八項任務,這八項任務包括研究檢索、研究篩選、證據總結、試驗組設計、入排標準制定、終點選擇、樣本量估計及完成情況評估。通過在五個當前最先進的大模型上開展實驗,研究團隊發現通用模型雖然具備一定的零樣本能力,但其表現尚不足以勝任高風險、要求嚴謹的臨牀試驗場景。
而本次工作不僅提供了一個高質量的數據基礎,還構建了可用於訓練、評估和推動臨牀試驗 AI 研究的系統平臺,有望爲開發更具專業性和實用性的智能系統奠定堅實基礎。
(來源:https://arxiv.org/pdf/2505.16097)
本次研究成果具有廣泛的應用前景,預計能在以下幾個方面發揮重要作用:
首先,TrialPanorama 數據庫可以作爲醫藥研發和醫學事務中基於 AI 的知識發現平臺。例如,人們可以藉助該數據庫檢索某一適應症下既往的治療手段及其結果、正在研發中的同類藥物等關鍵信息,從而輔助制定更科學、更具前瞻性的臨牀試驗方案。
其次,該數據庫爲訓練大模型提供了數據基礎。由於其結構清晰、覆蓋全面,非常適合用於生成高質量的訓練樣本,推動更貼近臨牀場景的專用語言模型的開發。同時,研究團隊發佈的 benchmark 也爲評估現有及未來的大模型在臨牀試驗任務中的表現提供了統一、專業的測試框架。
最後,對於當前越來越多專注於臨牀試驗領域的 AI Agent 系統來說,TrialPanorama 提供了結構化、標準化的數據資源,並可以通過集成模型上下文協議(MCP,Model Context Protocol)服務器實現快速接入與部署,從而助力構建高可靠性、高專業度的垂類 AI Agent,爲臨牀研發帶來賦能。
(來源:https://arxiv.org/pdf/2505.16097)
多年前,王子豐就開始研究 AI,同時做一些 AI for healthcare。一開始進入這個方向時,他覺得有很多的“low-hanging fruit”,他認爲只要把大模型用上、Agent 搭起來,然後就可以開展很多臨牀試驗的任務。但是,當他真正在項目中和醫生、藥廠的研發人員、銷售等各類角色深度接觸之後,王子豐才意識到很多現實中的核心需求,其實並沒有被很好地抽象成 AI 問題然後被做 AI 的人們注意到。
這中間有很多令人反思的時刻。比如他經常看到一些很酷炫的大模型demo,但是藥廠的合作方告訴他,他們可能也會去嘗試一下,然而很多時候實際效果往往不能達到可用的程度,或者說由於公司的合規性要求這些工具還不能夠嵌入他們的工作流。
而作爲一名 AI 研究者,王子豐認爲得學會放下自嗨的技術視角,真正去傾聽用戶的痛點,理解他們的工作流程、合規限制和實際目標,然後再回過頭來重新定義問題,想辦法用 AI 去解決。
同時,這個“對話”和“重構”的過程,是王子豐在本次研究之中認爲最有價值、也是最難忘的部分。這不僅僅凸顯了當前的一些技術挑戰,更是對於跨學科協作、產品思維、溝通能力的一種錘鍊。
至於創業,它對王子豐來說也是一種自然的延伸。王子豐覺得做應用研究的人去創業其實非常合適。一方面你能從一線看到很多真實又有挑戰的問題,另一方面你也有機會把研究成果真正落地,幫助到藥廠、醫生甚至患者。這種“從問題中來,到應用中去”的過程,非常充實,也讓王子豐找到了科研之外的成就感。
正因此,王子豐聯合創辦了 Keiji.AI,在該公司他主要負責 AI 算法和應用的開發。該公司由王子豐的博士導師 Jimeng Sun 教授領銜,團隊成員主要來自美國伊利諾伊大學香檳分校的研究團隊。公司致力於將研究團隊多年來在 AI 醫療和臨牀試驗領域的研究成果轉化。
基於這一背景,研究團隊開發了 TrialMind 平臺,集成了多種 AI Agent 和工作流程,並接入研究團隊自建的 TrialPanorama 數據庫,支持臨牀試驗的方案設計、隊列抽取、數據分析、患者招募等關鍵環節的智能化加速。
目前,研究團隊的客戶和合作夥伴包括多家制藥公司(如Takeda、Abbvie、Regeneron)、真實世界數據公司(如 Medidata、Guardant Health),以及大型 CRO(如 IQVIA)。公司正處於快速發展階段,正在積極推進融資並擴大團隊。而基於上述工作,他們正在基於本次數據庫開發臨牀試驗的垂類 AI Agent 和模型。
參考資料:
1.https://arxiv.org/abs/2406.17755
2.https://arxiv.org/abs/2501.16255
3.https://www.nature.com/articles/s41467-024-53081-z
4.https://arxiv.org/abs/2410.21591
5.https://arxiv.org/abs/2505.16100
6.https://arxiv.org/abs/2504.00934
7.https://arxiv.org/abs/2505.16097



