在走向通用人工智能的道路上,機器人領域長期面臨着“莫拉維克悖論”的限制:許多對人類來說很困難的事,AI 卻很擅長;而許多對人類來說輕而易舉的事,AI 反而做不到。
例如,讓計算機在智力測試或棋類遊戲中擊敗人類或許相對容易,但要讓機器人像一歲孩子那樣具備對物理世界的感知和運動本能,卻難如登天。
近年來,大語言模型展現了對人類知識的壓縮與生成能力,但在物理交互層面,如何讓智能體理解“動作”與“環境”之間複雜的因果關係,始終是具身智能尚未攻克的難題。
近日,英偉達(NVIDIA)與其通用具身智能研究團隊(GEAR)共 30 個作者聯合發佈了一項代號爲 DreamDojo 的最新研究成果,試圖從根本上影響機器人學習物理世界的方式。

圖 | 團隊論文:DreamDojo:基於大規模人類視頻的通用機器人世界模型(來源:GitHub)
這項工作並沒有依賴傳統的、昂貴的機器人遙操作數據堆疊,而是另闢蹊徑,構建了一個包含 44,000 小時、第一人稱視角人類視頻的龐大數據庫,並以此訓練出了一個能夠通用化的機器人世界模型。
這一模型不僅能夠逼真地生成物理交互視頻,更關鍵的是,它讓機器人首次具備了可控的“想象力”。即在執行動作之前,在潛意識中預演人類世界物理後果的能力。

(來源:論文)
世界模型的概念已經並不新鮮。從早期的遊戲環境模擬到自動駕駛中的軌跡預測,預測未來狀態一直是智能決策的核心。然而,在開放世界的機器人操作任務中,世界模型的構建面臨着獨特的挑戰。與有着清晰規則的電子遊戲或結構化道路不同,家庭、工廠或辦公室等非結構化環境充滿了不確定性。
例如一個看似簡單的“抓取水杯”動作,涉及物體材質、摩擦力、液體晃動以及機械臂動力學等無數變量。此前的視頻生成模型,如 OpenAI 的 Sora 或 Google 的 Genie,雖然在畫面生成質量上取得了突破,但它們大多缺乏精確的動作控制接口,難以直接服務於機器人的決策迴路。
而此次 DreamDojo 的核心突破就在於此,它證明了通過大規模的人類視頻預訓練,結合創新的“潛在動作”(Latent Actions)表徵,可以有效地彌合人類與機器人之間的“具身差異”(Embodiment Gap),從而讓機器人獲得對物理規律的通用理解。
借力人類視頻突破數據缺口
長期以來,制約機器人基礎模型發展的最大瓶頸在於數據。儘管互聯網上充斥着萬億級別的文本和圖像數據,但高質量的“機器人操作數據”。即包含精確動作指令(Action Labels)和環境反饋的序列數據卻極度稀缺。目前主流的機器人數據集,如 Open X-Embodiment,雖然彙集了多個實驗室的數據,但在場景多樣性和物理交互的豐富度上,仍遠不足以覆蓋真實世界的複雜性。
英偉達團隊意識到,單純依靠擴大機器人實體數據的採集規模是不現實的。採集成本高昂、硬件損耗大、場景佈置繁瑣,這些因素限制了數據的增長速度。相比之下,人類在日常生活中每時每刻都在與物理世界交互,而這些交互過程如果被記錄下來,本身就是蘊含着豐富物理知識的寶庫。
爲了挖掘這一寶庫,研究團隊構建了名爲 DreamDojo-HV(Human Videos)的數據集。這是一個規模驚人的數據集合,包含了約 44,711 小時的第一人稱視角視頻。
這些視頻並非來自於受控的實驗室環境,而是廣泛採集自真實世界,涵蓋了家庭烹飪、工業維修、手工製作、日常清潔等超過 6,000 種獨特的技能和 1,000 多種不同的場景。爲了保證數據的多樣性,團隊還特別整合了 EgoDex 等現有的高質量數據集,使得 DreamDojo-HV 在規模上比此前機器人學習中使用的最大視頻數據集還要大出幾個數量級。
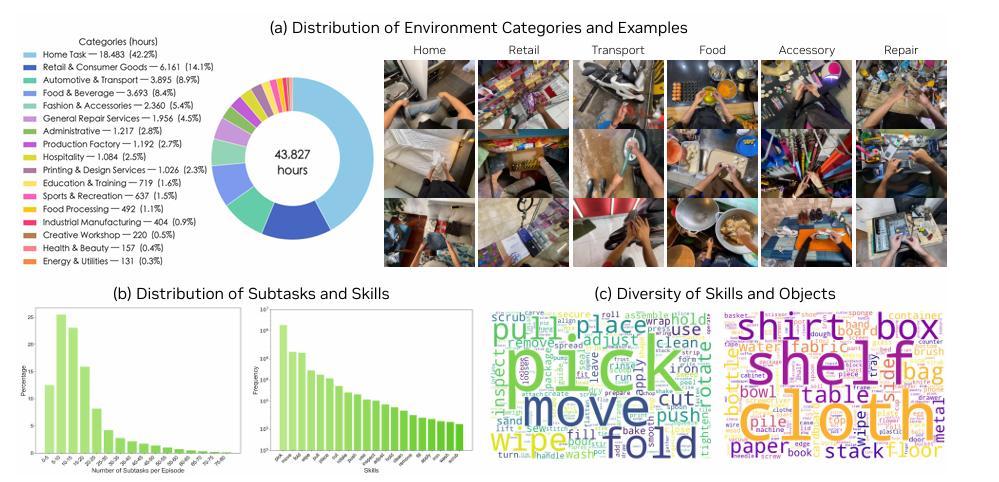
圖 | DreamDojo-HV(Human Videos)的場景分佈(來源:論文)
然而,直接使用人類視頻訓練機器人模型也面臨着一定困難。最直觀的問題是:人類的手臂結構與機器人的機械臂完全不同,且人類視頻中並不包含機器人的關節角度、力矩等控制信號。這種缺失導致模型難以直接學習“動作”與“結果”之間的映射關係。
逐幀推理下一個動作
爲了解決無標籤人類視頻的利用問題,DreamDojo 引入了一項關鍵技術:連續潛在動作(Continuous Latent Actions)。
在傳統的機器人學習中,模型通常直接預測離散的關節動作或末端執行器位姿。但在處理海量無標註的人類視頻時,這種方法行不通了。因此,研究人員設計了一個基於時空 Transformer 的變分自編碼器(VAE)作爲“潛在動作模型”。
這個模型的作用類似於一個能夠理解動作本質的“翻譯官”。它不關注具體的關節如何旋轉,而是通過觀察視頻中連續幀的變化,提取出一個低維的、連續的潛在向量。這個向量代表了導致環境發生變化的“意圖”或“力學特徵”。

圖 | 潛在動作模型(來源:論文)
通過這種設計,潛在動作成爲了連接人類視頻與機器人控制的通用橋樑。在預訓練階段,模型通過自我監督的方式,學習如何從像素變化中推斷出潛在動作,並利用這些潛在動作預測下一幀畫面。
這使得 DreamDojo 能夠在沒有顯式動作標籤的情況下,從 44,000 小時的視頻中汲取物理世界的因果邏輯。例如,它通過觀察無數次“手推開門”的視頻,學會了“施加推力”這一潛在動作會導致“門打開”這一視覺結果的物理規律,而這種規律對於機器人來說同樣適用。
在具體的模型架構上,DreamDojo 建立在英偉達此前發佈的 Cosmos-Predict2.5 基礎之上。這是一個強大的潛在視頻擴散模型(Latent Video Diffusion Model),原本用於通用的視頻生成。爲了適應機器人的實時控制需求,研究團隊對其進行了深度的改造。
爲了提高動作的可控性,團隊放棄了絕對關節位置的輸入方式,轉而採用“相對動作”(Relative Actions)作爲條件。實驗表明,相對動作能夠更好地聚焦於物體與手部的交互變化,減少了背景環境對模型注意力的分散。
同時,針對視頻生成中常見的“因果混淆”問題,即模型難以區分動作是原因還是結果。研究團隊提出了一種“分塊注入”(Chunked Injection)策略。
他們將未來的動作序列打包成塊,一次性輸入到模型的每一幀生成過程中。這種強先驗信息強制模型關注長時程的動作影響,從而顯著提升了生成視頻的邏輯連貫性。
此外,爲了確保生成的物理過程符合現實世界的連續性,研究團隊還引入了專門的時間一致性損失函數(Temporal Consistency Loss)。這一函數約束了物體在時間軸上的運動軌跡,防止了視頻生成中常見的物體閃爍、憑空消失或形狀突變等僞影現象,確保了物理模擬的高保真度。
從慢速擴散到超快實時“想象”
擁有一個懂物理的模型只是第一步,對於機器人應用來說,推理速度至關重要。傳統的視頻擴散模型生成一幀高質量畫面往往需要數十次迭代,耗時數秒,這對於需要毫秒級響應的機器人控制迴路來說是不可接受的。
爲了解決這一難題,DreamDojo 採用了一種名爲“自強迫”(Self Forcing)的蒸餾技術,成功將原本笨重的雙向注意力擴散模型轉化爲高效的自迴歸模型。
這一過程通過“教師-學生”訓練模式實現:首先利用高精度的教師模型生成大量的軌跡數據,然後訓練學生模型去模仿這些軌跡。但在蒸餾過程中,學生模型不僅要學習單幀的生成,還要學習如何在僅有極短歷史上下文的情況下,預測未來的長期演變。
這一蒸餾過程將模型的推理步數從原本的 35 步大幅壓縮至 4 步。最終,DreamDojo 在單張 NVIDIA H100 GPU 上實現了 10.81 FPS(幀/秒)的實時推理速度。這意味着機器人可以在不到 0.1 秒的時間內,在“腦海”中生成未來的視覺反饋。
這不僅滿足了實時控制的要求,更讓長時程的交互模擬成爲可能。實驗顯示,經過蒸餾後的模型能夠連續生成長達 1 分鐘(約 600 幀)的穩定視頻,且在長時間跨度下依然保持對物體及其物理屬性的記憶,沒有出現常見的畫面崩壞。
打通“虛實”邊界的實際應用
DreamDojo 的價值遠不止於生成逼真的視頻,其實質是爲機器人提供了一個低成本、高保真的“試錯空間”。基於這一世界模型,英偉達團隊展示了三項核心應用,充分證明了其在機器人研發與部署流程中的潛力。
首先是策略評估(Policy Evaluation)。在機器人開發中,驗證一個新的控制策略通常需要實機測試,這不僅效率低下,還伴隨着硬件損壞的風險。DreamDojo 提供了一個替代方案:將策略部署在世界模型中,讓機器人在虛擬的視頻流中執行任務。
研究人員在 AgiBot 機器人的水果包裝任務中進行了驗證,結果令人振奮:DreamDojo 模擬出的任務成功率與真實世界的成功率呈現出極高的線性相關性(Pearson 相關係數高達 0.995)。這意味着開發者可以放心地在模擬環境中篩選最優策略,而無需在現實世界中進行成百上千次的物理實驗。
其次是基於模型的規劃(Model-based Planning)。利用 DreamDojo 的預測能力,機器人可以在執行動作之前,在“思維”中並行推演多種動作方案的結果。
例如,在抓取一個被遮擋的蘋果時,機器人可以預演直接抓取和先移開遮擋物兩種方案,DreamDojo 會即時生成相應的未來視頻。通過評估視頻中的任務完成度,機器人可以選擇最優路徑。實驗表明,在引入這種在線規劃機制後,機器人在複雜長程任務中的成功率相比直接執行策略提升了近兩倍。
最後是實時遙操作(Live Teleoperation)。藉助蒸餾後的高推理速度,操作員可以通過 VR 手柄實時驅動虛擬環境中的機器人。DreamDojo 能夠即時響應操作員的動作,並生成相應的視覺反饋。這種“所見即所得”的零延遲體驗,不僅爲遠程控制提供了新的界面,也爲人類向機器人演示覆雜技能提供了更直觀的數據收集方式。

圖 | 實時遙操作:可以使用 PICO VR 控制器實時遙操作虛擬 G1 機器人(來源:論文)
當然,DreamDojo 並非完美無缺。英偉達團隊在報告中坦誠地指出了當前模型的侷限性。儘管在大部分日常場景中表現優異,但在面對一些極端動態(如快速揮手、物體高速碰撞)或涉及複雜流體動力學(如倒水時的水流湍流)的場景時,生成的視頻仍會出現物理失真或模糊。
此外,雖然模型在未見過的物體上展現了良好的泛化性,但對於完全陌生的物理機制(例如具有特殊彈性的軟體材料),其預測能力依然有限。
此外,目前的 DreamDojo 主要側重於視覺層面的物理模擬,尚未整合觸覺、聽覺等多模態信息。對於像“盲插鑰匙”或“判斷物體重量”這樣極度依賴觸覺反饋的精細操作任務,單純依靠視覺預測的世界模型仍顯得力不從心。未來的研究方向可能需要探索如何將觸覺信號引入潛在動作空間,構建更加全能的多模態世界模型。
參考鏈接:
https://arxiv.org/abs/2602.06949
運營/排版:何晨龍