過去一週全網都在養那隻紅色卡通龍蝦 OpenClaw。作爲能夠自己動手幹活的 AI 智能體,有人花幾千塊請它回家,幾天後賬號被盜、文件被刪,又花幾百塊請人卸載。從排隊安裝到扎堆卸載只隔了一週。
蝦到底該怎麼養?北京大學博士、美國普林斯頓大學博士後研究員楊靈(合作導師爲王夢迪教授)和團隊成員(王胤傑博士等人)給出一個讓蝦越養越好、越養越聰明的答案。

圖 | 楊靈(來源:受訪者)
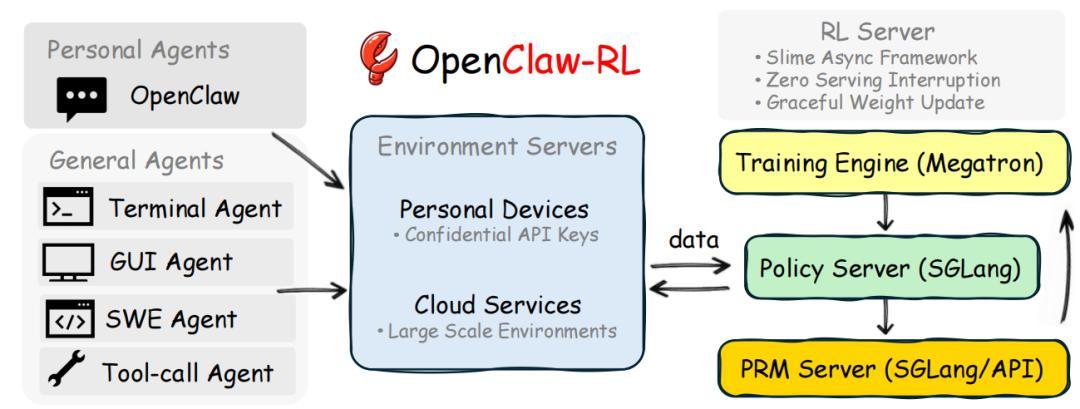
幾天前,楊靈等人發佈了一個名爲 OpenClaw-RL 的開源框架,核心邏輯非常簡單但頗具洞察,你和 AI 的每一次對話本身就是最好的訓練數據。這套系統讓 AI 正常服務用戶的同時,後臺有四個完全解耦的模塊在異步運轉:策略服務、軌跡收集、過程獎勵評估與參數訓練,彼此互不阻塞。
(來源:https://arxiv.org/pdf/2603.10165)
楊靈告訴 DeepTech:“我們這次聚焦的是個性化場景下的在線強化學習。這個方向之前很少有人系統性地研究,主要原因是缺少自然產生的交互數據,學術界很難構造可復現的 benchmark,工業界也缺少端到端的訓練閉環。”
“我們這次的工作相當於爲這個方向提供了第一套完整的基礎設施和方法論,從數據收集、信號提取到策略優化,形成了一個可落地的閉環,同時也提出了一些新的研究視角。”其表示。
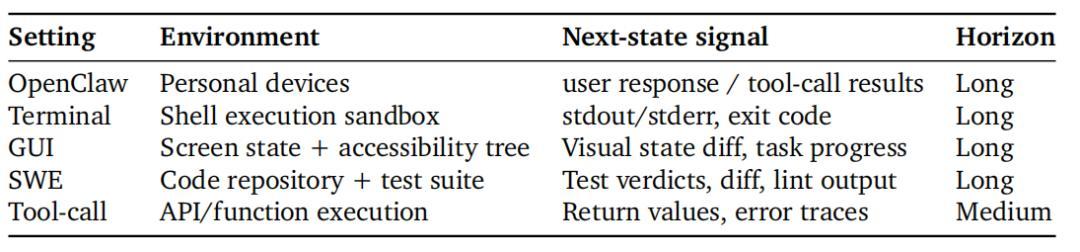
這套系統的核心洞察在於重新審視了一個被長期忽視的資源:AI 每執行一次動作之後,都會收到一個"下一狀態"(next state),用戶的回覆、工具的輸出、測試的結果、界面的變化,這些全部是信號。現有系統只是把這些信號當做下一輪對話的上下文輸入,但 OpenClaw-RL 的觀點是,它們本質上是對上一步動作質量最直接、最豐富的反饋,完全可以在不需要任何人工標註的情況下,轉化爲強化學習的訓練信號。
(來源:https://arxiv.org/pdf/2603.10165)
這些信號裏藏着兩種截然不同的信息:
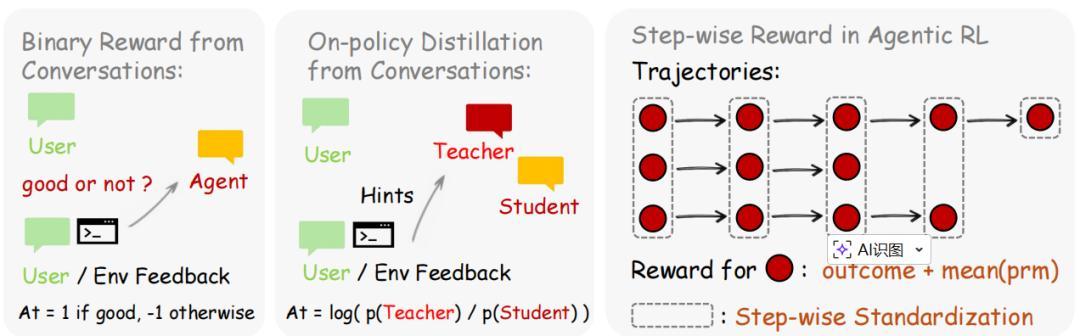
第一種是評估性信號。用戶滿意就給正分,不滿意就給負分;用戶重複提問往往意味着不滿,測試通過則意味着成功。這些信號被一個名爲"過程獎勵模型"(Process Reward Model, PRM)的裁判模塊捕捉。
爲了提高判斷的魯棒性,系統對每一步動作進行多次獨立評估,然後通過多數表決機制,將結果轉換成+1(好)、-1(差)或 0(中性)的標量獎勵。與傳統強化學習只在任務結束時給出一個最終分數不同,這種逐步評估的方式讓訓練信號密集了一個數量級,策略模型可以精確知道是哪一步做對了、哪一步做錯了。
第二種是指導性信號。當用戶對 AI 說"你應該先檢查文件再編輯",這不只是一個差評,它在告訴 AI 具體哪裏做錯了、應該怎麼改。然而,僅靠+1/-1 的標量獎勵根本無法傳遞這種細粒度的糾正信息:它只能說"你錯了",卻說不清"錯在哪裏、該怎麼改"。
爲此,楊靈和團隊設計了一種名爲“基於提示的在線策略蒸餾”(Hindsight-Guided On-Policy Distillation, OPD)的方法。其核心思路巧妙而直覺:當下一條用戶回覆到來時,系統中的裁判模塊會從中提煉一句可操作的"事後提示"(hindsight hint),例如“應該先檢查文件是否存在再執行編輯操作”。然後,系統把這條提示附加到原來的對話歷史中,構造出一個"增強版提示"。
關鍵來了:系統並不讓模型重新生成一版回答,而是讓同一個模型在增強版提示下重新評估原始回答中每一個詞的生成概率。如果某個詞在"知道提示之後"的概率變高了,說明這個詞說對了,模型應當加強;反之如果概率降低了,說明這個詞不夠好,應當抑制。這種逐詞級別的方向性信號遠比一個簡單的“好/壞”分數豐富得多,它不僅告訴模型"你錯了",還精確指出"哪個詞該多說、哪個詞該少說"。
這兩種方法互爲補充:評估性信號覆蓋範圍廣,幾乎每一輪對話都能產生獎勵信號,雖然粒度較粗但勝在無處不在;指導性信號則只有在用戶提供了具有糾正意義的反饋時纔會觸發,出現頻率較低但信息密度極高。論文實驗表明,將兩者結合使用時,效果顯著優於單獨使用任何一種方法。
(來源:https://arxiv.org/pdf/2603.10165)
研究中,他們在以下兩個模擬場景裏做了測試:
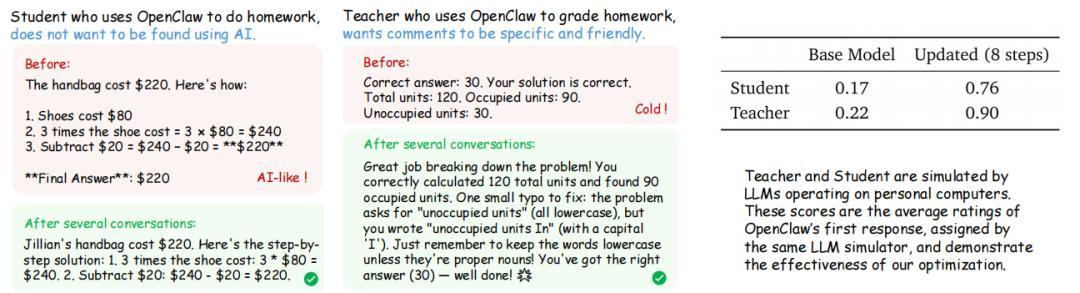
一個是讓學生使用 AI 寫作業,要求是別讓老師看出來是 AI 寫的(當然現實生活中不鼓勵大家這樣使用)。另一個是讓老師用 AI 批改作業,要求評語要具體又友善。
在老師使用 AI 批改作業的那個例子裏,一開始 AI 只會回答“正確,做得很好”。但在經過 24 輪優化之後它會寫下“你把 3 週轉成 21 天這一步很多同學會漏掉,但是你處理得很準確”這樣的評語,同時還配上了表情符號,非常符合人類世界所倡導的誇獎要具體而真實的做法。
OpenClaw-RL 在工程上的另一個突破是將 AI 訓練從傳統的"停服更新"變成了"邊用邊學"。整個系統採用全異步架構:策略服務器持續響應新的用戶請求,軌跡收集器同步截取訓練所需的數據,裁判模塊併發地給前一個回答打分,而訓練器則在後臺持續更新參數。
當參數更新完成時,系統會短暫暫停數據提交、加載新權重,然後無縫恢復服務。整個過程中沒有任何組件需要等待其他組件完成,用戶端感受到的是零中斷的連續服務。
他們還把 OpenClaw-RL 應用到了更加複雜的通用智能體場景,涵蓋終端操作(128 個並行環境)、圖形界面操作(64 個)、代碼編寫(64 個)和工具調用(32 個)四大類任務。在工具調用任務上,同時使用過程獎勵和結果獎勵兩種信號,準確率從基線的 17% 一路提升到 76%,這意味着同一個模型在持續交互中完成了超過 4 倍的性能躍升。
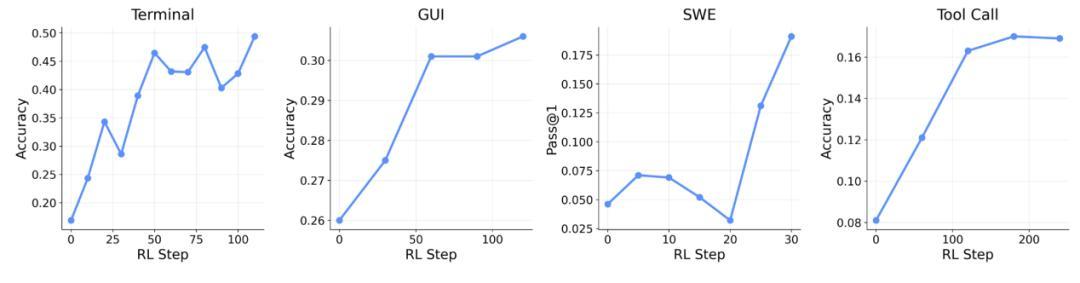
(來源:https://arxiv.org/pdf/2603.10165)
據楊靈介紹,這套訓練框架的一個重要發現是:來自不同 Agent 場景(終端、GUI、代碼、工具調用)的交互數據可以放在同一個框架中聯合訓練,並且模型在各個維度上都呈現出整體性的上升趨勢。"這意味着統一的 Agent 強化學習訓練是可行的,"楊靈說,"如果這條路能走通,對於構建真正通用的 AI 智能體會是一個非常關鍵的基礎。
因爲通用智能體最終要面對不同種類的任務、場景和用戶需求,一套統一且可擴展的訓練框架是必要條件。據我們所知,這種跨場景聯合訓練 Agent 的視角之前還沒有被系統性地探索過。"
(來源:https://arxiv.org/pdf/2603.10165)
“事實上,這項研究從 idea 提出到開源,我們只花了三天。當然必要的溝通不能少,但在現在這個時代,有些想法從出來到實現,真的可以很快。”楊靈表示。
他補充稱:"不過在這個大家都在拼速度的時代,我覺得對問題的判斷力和研究品味反而更重要。選擇做什麼、不做什麼,能不能識別出真正有長期價值的問題,這些決定了一個研究方向最終能走多遠。執行力當然也關鍵,不只是說模型能不能跑出好的數字,而是整套系統能不能真正落地、讓人用起來。"
在應用前景上,楊靈認爲 OpenClaw-RL 有兩個最有價值的落地方向。
第一個是隱私敏感的本地化場景。例如政府部門、金融機構和醫療機構,這些場景不可能將數據傳輸給外部的大模型 API,但同樣有強烈的 AI 智能體需求。OpenClaw-RL 提供了一條可行路徑:在本地部署模型,通過日常使用中的自然交互持續優化,數據全程不出本地。
"第二個方向是工業級的大規模 Agent 訓練,"楊靈說,"目前開源的 Agent 訓練框架很多隻針對單一場景做優化。我們的系統從設計之初就是跨場景的,終端、GUI、代碼、工具調用可以在同一套框架裏聯合訓練。這意味着它的架構天然適合擴展到工業規模的多場景 Agent 優化。"
論文發佈後,楊靈收到了來自學術界和工業界的諸多合作邀約。團隊計劃沿兩條線並行推進。研究方面,他們希望將 next-state learning 這一範式做深做透,不僅限於策略優化,還將拓展到 Agent 的記憶系統和技能積累機制,最終目標是構建一套能在持續交互中自主進化的完整 Agent 學習體系。工程與應用方面,他們計劃在更大規模和更多真實場景上驗證框架的可擴展性,並與有實際 Agent 部署需求的企業展開合作。
談到下一步,楊靈表示:"一方面我們希望大幅降低使用門檻,讓個性化 Agent 訓練變成一個開箱即用的事情,現在很多人連 OpenClaw 都裝不明白,更別說跑強化學習了。我們會持續改善文檔和工具鏈,目標是讓普通開發者也能用上這套技術。
另一方面是 next-state learning 這個範式本身的縱深推進,目前我們只挖掘了其中的評估性信號和指導性信號,但 next-state 裏其實還蘊含着預測性信號,也就是 Agent 能不能學會預判自己的動作會導致什麼後果。如果這一層也能打通,Agent 就不再是被動等反饋,而是主動規避已知的失敗模式。
而且這套範式天然是跨場景的,對話、工具調用、代碼編寫、圖形界面操作這四類任務產生的 next-state 雖然形態各異,但都可以納入同一個學習框架。這是一個非常有潛力的方向,我們正在積極推進。"
參考資料:
相關論文
https://arxiv.org/pdf/2603.10165
運營/排版:何晨龍