華爲縮小AI算力差距的策略,是一種典型的非對稱競爭。它是特定歷史時期和特定限制條件下的有效策略,爲中國未來突破國產光刻機和更先進工藝製程的國產AI芯片,爭取了寶貴的戰略窗口
文|吳俊宇
編輯 | 謝麗容
過去三年,中國、美國科技巨頭的大模型,絕大部分是英偉達的AI芯片上訓練出來的。國產選手和英偉達之間,隔着一道天塹。邏輯很簡單,英偉達不僅單卡性能更強,軟件生態也更完整。美國政府一直在限制對中國出售先進AI芯片。今年4月,美國商務部已限制英偉達對華出售特供中國市場的H20芯片。而H20事實上已經是英偉達芯片的性能閹割版。中國大陸買家理論上已無法通過正常渠道獲取英偉達的先進AI芯片。自主可控才能把命運掌握在自己手裏。昇騰910系列是中國企業使用最多的國產AI芯片,包括字節跳動、阿里、騰訊、百度、螞蟻金服等大型科技企業都在使用昇騰910。不過,過去三年,中國大部分科技大廠把昇騰910更多用在推理環節,而不是用作模型訓練。模型訓練是個複雜的系統工程。一個基礎大模型,通常在數萬枚先進AI芯片(如英偉達GB200/H200/H100)組成的算力集羣上,進行數週甚至數月的不間斷訓練。在萬卡集羣中,芯片、網絡、軟件隨時可能故障。集羣規模越大,故障概率就越高。一旦故障,訓練任務就會中斷,不僅浪費時間,還浪費算力。今年1月,某科技公司的一位戰略規劃人士透露,當時他們發現,昇騰910系列芯片單卡性能不夠強,且存在軟件生態不完善等問題。但英偉達的A800/H800/H20等芯片不斷被限制出售後,用國產AI芯片訓練大模型已被很多中國科技公司提上了議事日程。此時,華爲也取得了重要技術進展——用昇騰910訓練出了1350億參數的盤古Ultra和7180億參數的盤古Ultra MoE。華爲還用系統工程手段突破了昇騰910單卡性能相對不足的短板。今年4月-5月,華爲在預印本論文平臺arXiv先後公佈了兩篇技術論文,分別介紹瞭如何使用昇騰910訓練1350億參數盤古Ultra Dense(可譯爲,稠密)模型、7180億參數的盤古Ultra MoE(mixture of experts,可譯爲,稀疏或混合專家)模型。今年4月,華爲發佈了CloudMatrix 384“超節點”(“超節點”指把數十枚、數百枚AI芯片互聯)方案。它採取系統工程的策略,把384張昇騰910互聯在一起。這個方案克服了單卡性能不足的問題,讓整個系統性能更優。華爲爲此投入的研發團隊超過1萬人。包括華爲雲、計算產品線、海思、2012實驗室、數通產品線、光產品線等團隊都參與了“算力會戰”。華爲通過跨部門作戰的方式,把幾十年積累的各種能力用於解決散熱、供電、高速互聯網、大芯片在板可靠性等工程問題。(昇騰910 AI處理器 圖源/視覺中國)
如何低成本、高效率訓練出兩款大模型
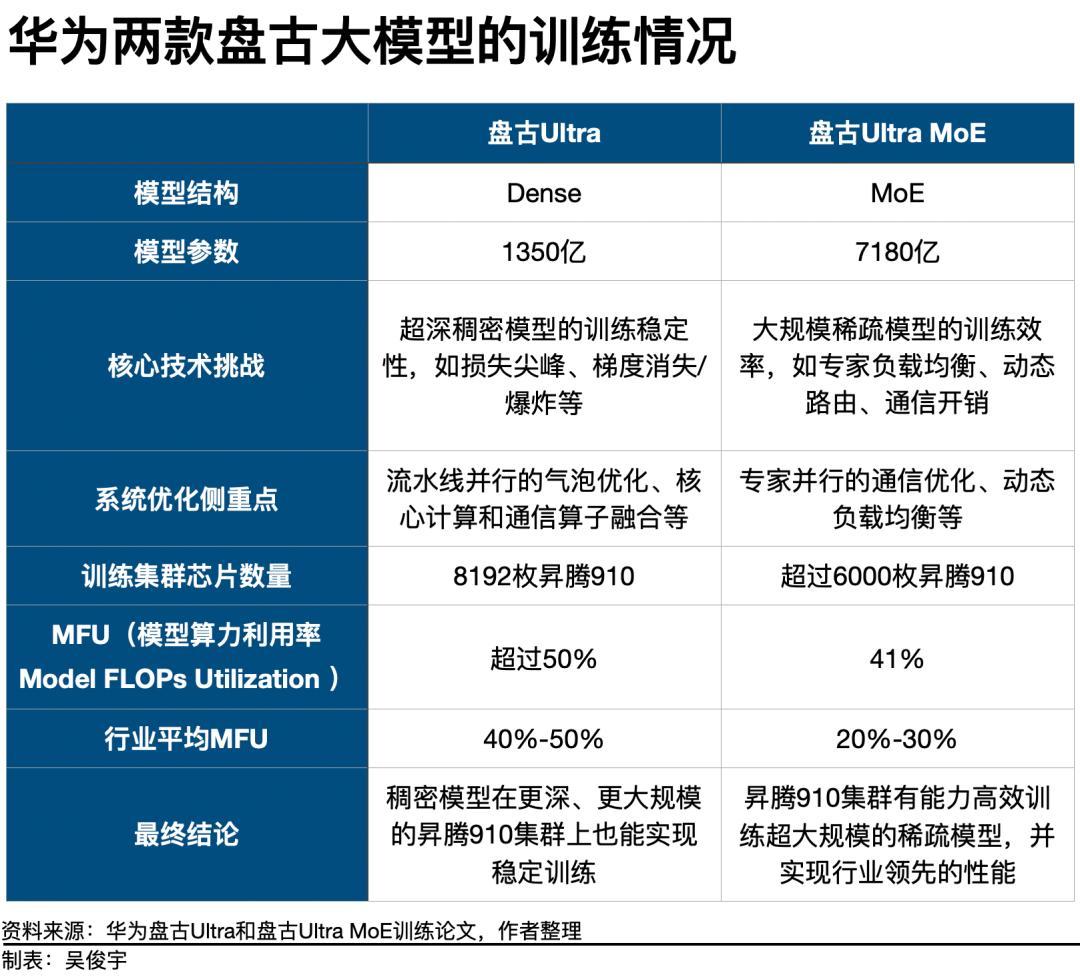
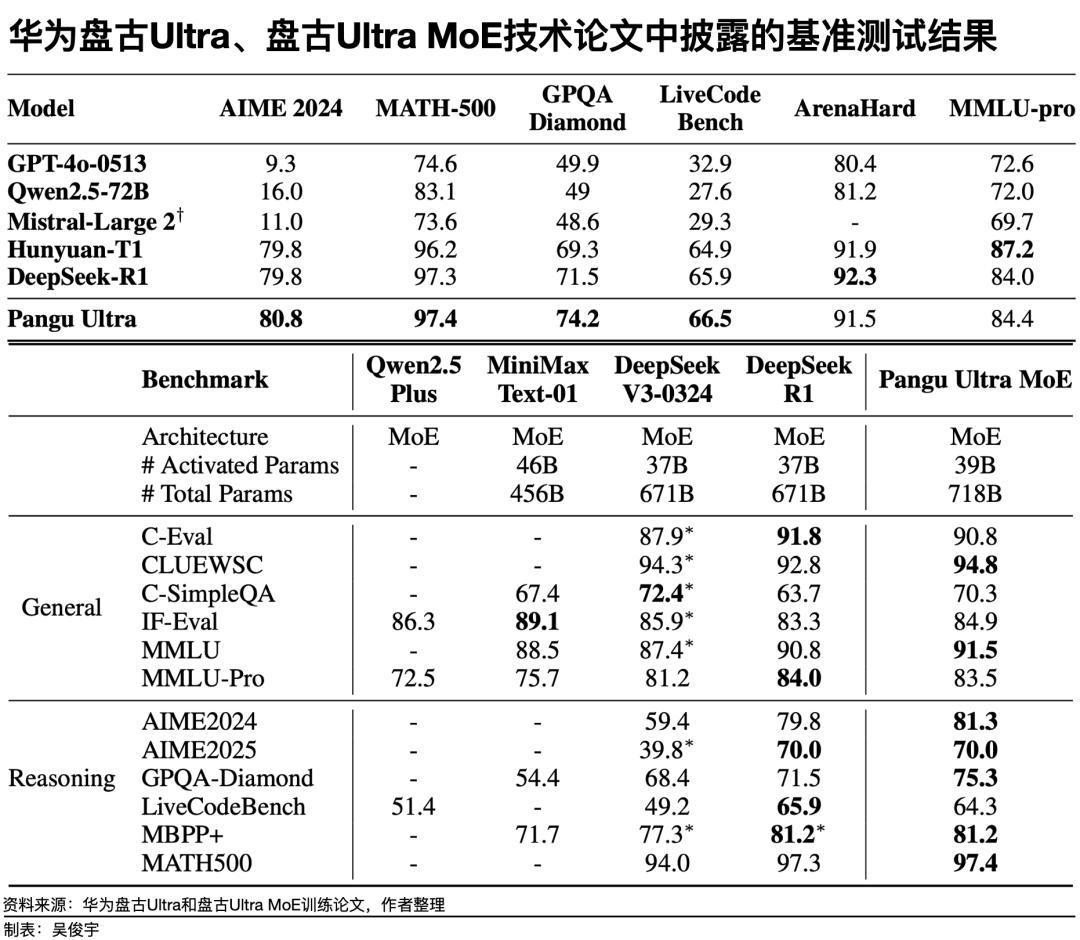
昇騰芯片如何突破大模型訓練這道難關?華爲的兩篇技術論文對此有非常詳盡的解釋。其中名爲《盤古Ultra:在昇騰NPU上突破高密度大語言模型的極限》的論文詳細分析了,如何用8192枚昇騰910系列芯片訓練1350億參數盤古Ultra這一Dense模型。訓練盤古Ultra的難點之一是,盤古Ultra有94個網絡層。這種深層稠密模型普遍訓練不穩定,容易出現“損失尖峯”。這會對模型造成“不可逆的性能損害”。爲此,華爲技術團隊通過“深度縮放三明治歸一化”等算法,解決了訓練穩定性問題。論文顯示,盤古Ultra模型性能在基準測試中和GPT-4o-0513、Llama 405B等行業領先的Dense模型不相上下。華爲另一篇主題爲《盤古Ultra MoE:如何在昇騰NPU上訓練你的大模型》的論文講述了,如何用6000多枚昇騰910系列芯片訓練7180 億參數的盤古Ultra MoE這款稀疏模型。訓練盤古Ultra MoE,要解決稀疏結構下,高效利用算力資源並減少通信開銷的問題。爲此,華爲技術團隊採用了模擬仿真的方式爲昇騰910“量身定做”了模型參數和模型結構。盤古Ultra MoE使用了256個專家模型平衡性能、效率。專家調度、通信開銷和負載均衡等系統問題最終也被攻克,這取得了不錯的效果。在基準測試中,盤古Ultra MoE與行業領先的稀疏模型DeepSeek-R1性能相當。(華爲兩篇技術論文,分別講述瞭如何在昇騰910系列芯片的集羣上訓練Dense模型和MoE模型 圖源/華爲在arXiv上公佈的預印本論文)一位華爲技術專家介紹,盤古Ultra和盤古Ultra MoE實現了長期穩定的訓練。在盤古大模型訓練過程中,華爲技術團隊積累了故障快速恢復的技術。過去算力集羣出現故障後,需要數小時才能恢復,現在可實現分鐘級恢復。對企業客戶來說,昇騰910能做到穩定訓練大模型還不算完全具備競爭力。它必須低成本、高效率纔有實際意義——這需要關注MFU(模型算力利用率Model FLOPs Utilization)這個重要指標。在大模型訓練中,MFU是評估算力集羣效率的重要指標。MFU越高,意味着芯片利用率越高、訓練時間越短、訓練總成本越低。在訓練盤古Ultra這款稠密模型時,8192枚昇騰910組成的算力集羣,MFU超過50%。《財經》瞭解到,訓練Dense模型的行業基準MFU通常是40%-50%,超過50%屬於行業前列。華爲披露的最新數據顯示,在訓練盤古Ultra MoE這款稀疏模型時,6000多枚昇騰910芯片組成的算力集羣,MFU達到41%。這遠遠高於行業平均水平。《財經》瞭解到,稀疏模型比稠密模型,參數更大調度更復雜,因此MFU相對更低。訓練稀疏模型時,行業基準MFU通常是30%左右。一位華爲技術專家對《財經》表示,目前實驗室內,盤古Ultra MoE的MFU達到了45%。盤古Ultra MoE的預訓練尚未使用CloudMatrix 384。未來如果使用CloudMatrix 384訓練大模型,MFU還將進一步提升。目前,有很多大型科技公司的客戶對CloudMatrix 384感興趣。一位科技公司基礎設施負責人2024年11月曾向《財經》介紹,在模型訓練中的有效AI算力=單卡算力有效率×並行計算有效率×有效訓練時間。極端情況下,模型訓練過程中會浪費一半的算力資源。如何避免浪費是一個重要課題,算力效率越高,訓練成本就越低。昇騰910的集羣目前可以實現穩定訓練,且能相對低成本、高效率地訓練大模型。那麼,華爲爲何此時公佈這些技術進展?一位華爲資深技術專家直言,以前大家選昇騰,並不是認爲昇騰先進,只是因爲美國斷供而被迫使用。但華爲志不在此,更希望讓行業瞭解昇騰的真實能力,也希望通過自身實力贏得客戶。目前,華爲針對互聯網行業和關鍵信息基礎設施行業的客戶,會派出中高級專家組成的“小巧靈突擊隊”,到一線現場支持客戶用好昇騰。硬件性能的代際差距,靠系統工程去彌平
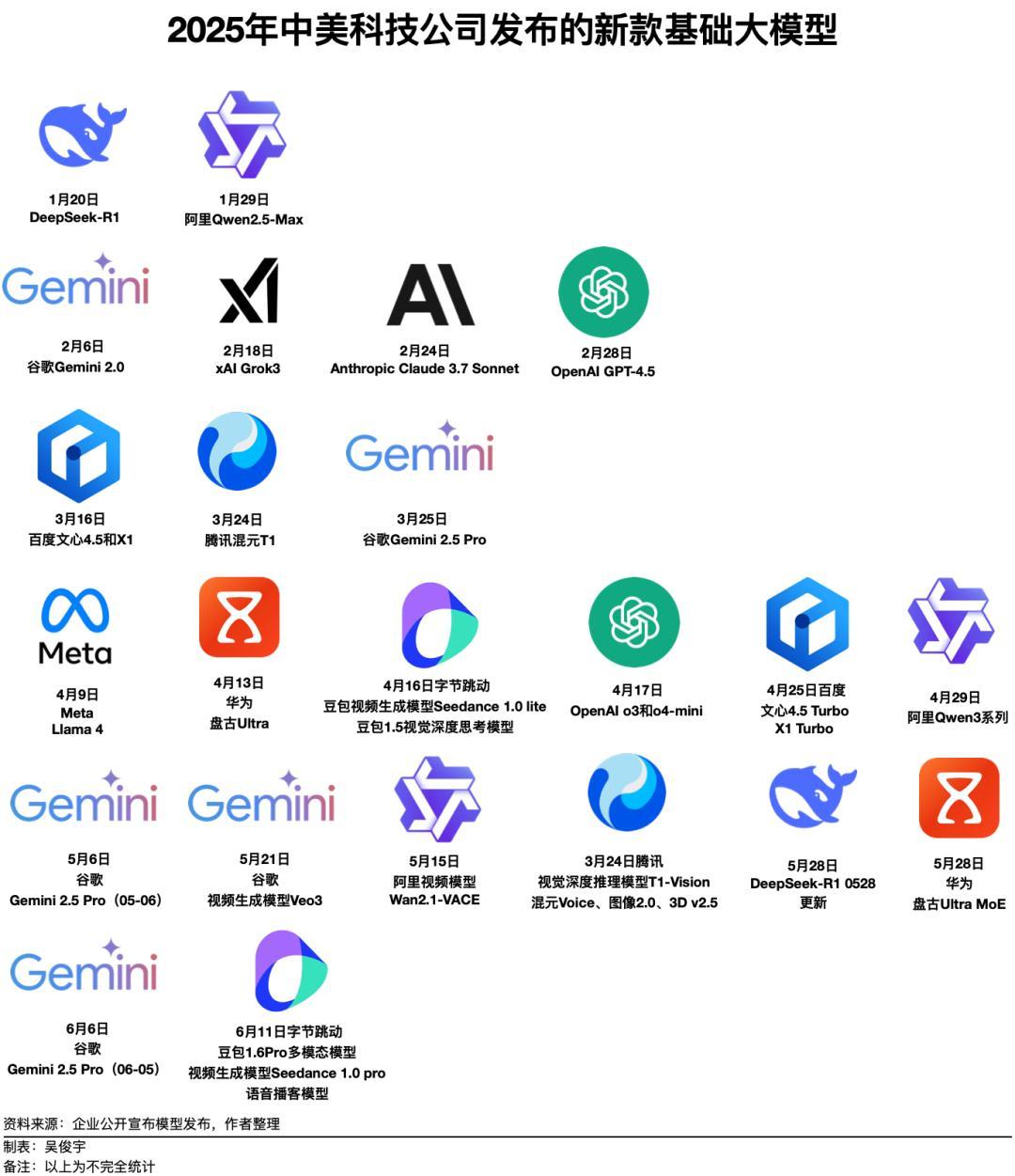
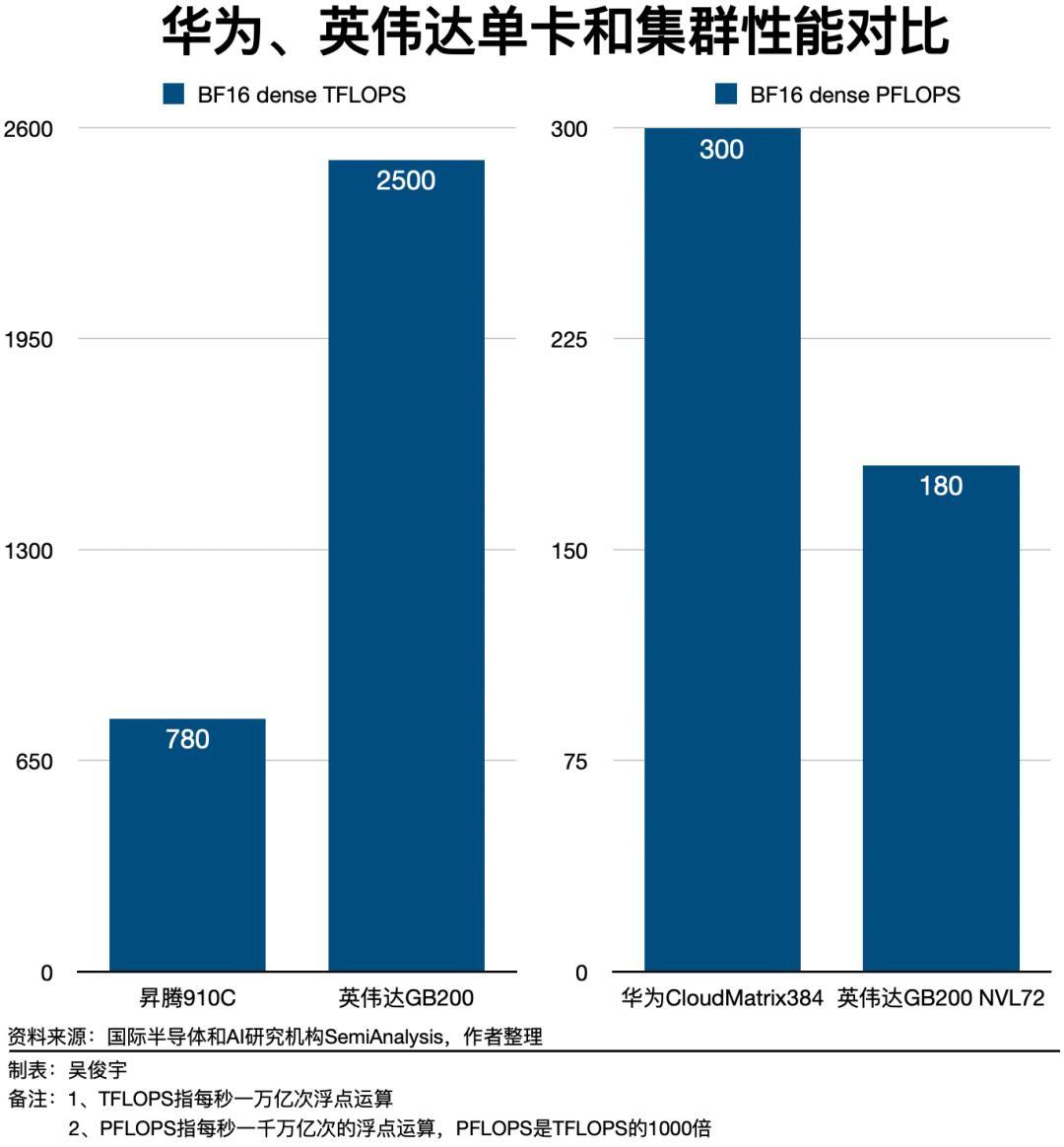
據《財經》不完全統計,截至2025年6月11日,中國和美國參與模型競爭的10家科技公司(包括華爲、字節跳動、阿里、騰訊、百度、DeepSeek、谷歌、OpenAI、Anthropic、xAI),在2025年剛剛過去的162天內發佈或迭代了至少23版大模型,平均每7天就會有一版新的大模型誕生。英偉達的AI芯片,幾乎每年都在迭代。英偉達2023年主力產品是A100,採用7納米工藝製程;2024年主力產品是H100/H200,採用4納米工藝製程;2025年主力產品是GB200,它由兩枚B200串聯成一塊芯片,採用3納米工藝製程。美國科技公司2025年初推出的大模型大多是在H100/H200集羣上訓練的,後續將在GB200集羣上訓練。這意味着,後續訓練大模型,需要更強、更多的芯片。昇騰910系列不可能原地踏步,它必須持續迭代,才能訓練出更好的模型。如果僅對比單卡性能,客觀說,昇騰910目前和英偉達GB200等旗艦芯片存在較大差距。但是,華爲正在採取系統工程手段突破算力集羣的峯值性能,挖掘昇騰910系列芯片的潛力。華爲的策略是,避開單顆芯片的直接對抗,轉而在系統架構層面,用超大規模集羣的方式,實現系統總性能的趕超。今年4月,華爲發佈的CloudMatrix 384,就是把384枚昇騰910芯片集成在16個機櫃,再通過光纜構建高帶寬、低時延的互連網絡組成一個單位集羣。好處是,這可以降低芯片並行計算的通信損耗,最終提升整體算力效率。CloudMatrix 384單位集羣拓展到萬卡時,它的性能損耗比傳統的8卡、16卡服務器集羣更小。國際半導體和AI研究機構SemiAnalysis分析稱,昇騰910單卡性能約爲780 TFLOPS(每秒1萬億次浮點運算),英偉達GB200單卡性能約爲2500 TFLOPS。昇騰單卡性能僅爲英偉達的GB200的三分之一。但華爲CloudMatrix 384集羣性能是300 PFLOPS(每秒1000萬億次的浮點運算,PFLOPS是TFLOPS的1000倍),GB200 NVL72的集羣性能是180 PFLOPS。華爲CloudMatrix 384集羣性能是英偉達GB200 NVL72的1.6倍。一位華爲雲人士今年4月曾對《財經》表示,英偉達GB200 NVL72使用銅纜做連接,但華爲CloudMatrix 384使用光纜做連接。光纜的缺陷是,安裝、維護難度更高。但華爲做通信多年,能做到低故障率。這帶來的收益是,可以做到低時延、高帶寬,壓榨出更高的峯值性能。這種大集羣模式還突破了中國HBM(High Bandwidth Memory,高帶寬內存)芯片性能更低的問題。去年12月,美國政府限制對中國出售高性能HBM芯片——這是先進AI芯片必不可少的零部件。中國後續無法獲得更高性能的HBM芯片。HBM性能低,會讓模型訓練變得擁塞,訓練時間變得更長。但國際半導體和AI研究機構SemiAnalysis分析認爲,CloudMatrix 384的芯片數量更多,集成的HBM個數也更多,因此擁有內存和帶寬也更大。因此,英偉達創始人黃仁勳今年5月28日接受媒體採訪時直言:“有很多基礎事實表明,華爲的技術可能與H200相當。”黃仁勳認爲,向市場提供CloudMatrix 384系統證明華爲的行動非常快,“這可以擴展到比我們最新一代Grace Blackwell(NVL72)更大的系統。華爲不會坐以待斃,他們想方設法尋找競爭的路徑。”種種現實條件制約不少的限制下,華爲的策略相對激進,核心是解決系統工程問題。爲解決網絡問題,華爲技術團隊根據計算系統的需求重新定義了互聯總線。爲實現算力高效調度,就要用操作系統實現資源池化。爲了讓系統平穩工作,還需要有大動態的供電。384枚芯片在一起發熱量巨大,則要使用散熱效率更高的液冷技術。一位華爲資深技術人士介紹,訓練大模型需要大系統。華爲技術團隊在計算、內存、通信、存儲、散熱、供電以及軟件等方面投入大量精力進行優化,最終實現系統性能更優。華爲幾十年在ICT領域,尤其是硬件工程、基礎軟件積累很深,因此有能力把複雜系統做好。上述華爲資深技術人士解釋,華爲基於中國的現實情況,解決中國的現實問題。華爲不簡單追求單點技術的路線,而是以面積換能力、以堆疊增容量、以集羣擴規模,通過超節點的系統工程創新,實現規模算力的領先和效能的最優。軟件生態迎來轉折點
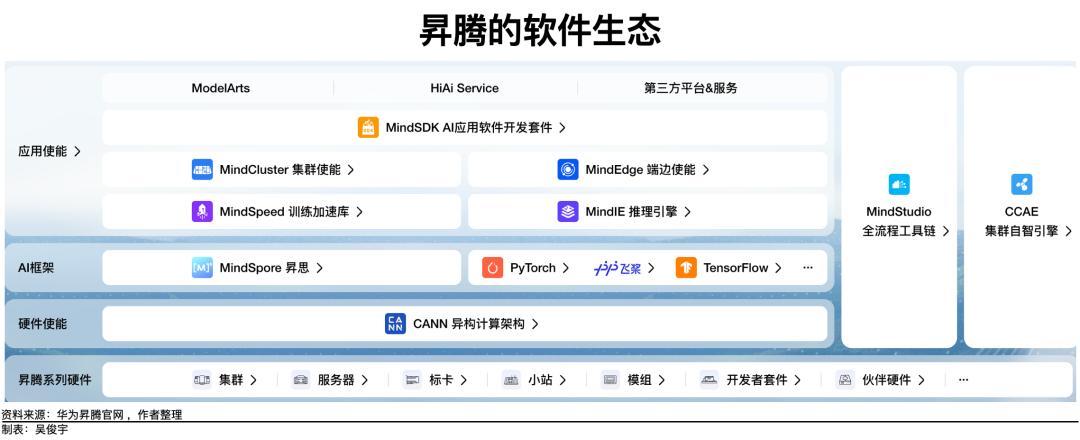
想要訓練出更好的模型,芯片要迭代,軟件生態也要不斷完善——這樣才能提升國產AI芯片的易用性。軟件生態一直被視爲是昇騰910系列芯片的重要短板。這在2023年之前尤爲明顯,但在2024年-2025年,昇騰的軟件生態已經有所好轉。所謂的軟件生態,主要包括兩大部分——芯片的開發工具棧(華爲CANN、英偉達CUDA)、模型的深度學習框架(華爲MindSpore、開源PyTorch/谷歌TensorFlow)。華爲的CANN、MindSpore起步相對更晚,它短時間內很難改變開發者長期形成的習慣。但積極信號是,一些彎道追趕的技術機會正在出現。過去,AI模型的架構比較分散,技術路徑不統一,各類算子有幾萬個,加上衍生的算子有十萬以上。這對英偉達這種CUDA生態做了十幾年的廠商來說並不難。開發者設計算子後,會第一時間適配英偉達的芯片。但對華爲等後發芯片廠商來說,想讓自家芯片支持所有主流模型,就必須開發、優化數萬個算子。正常情況下,這幾乎是不可能完成的任務。2023年之後,各種各樣的模型逐漸收斂到Transformer、Diffusion架構。以目前主流的GPT系列、Qwen系列、Llama系列、Deepseek-V3等模型爲例,它們使用的核心算子大約只有幾百個,這讓後發芯片廠商有了縮小生態差距的機會。一位資深算法工程師對《財經》解釋,算子融合、淘汰性能不足的算子後,需要開發的算子數量的確在大幅減少。如今只需要專注開發有限的算子,適配工作量大大減輕。因此,生態差距有希望縮小。一位華爲資深技術人士介紹,華爲已經開發補齊了高質量、高性能的基礎算子,並把這些算子深度開放給客戶。國內頭部客戶很快就適配了他們自己的模型和應用。其次,AI代碼生成技術正在普及。這也讓後發芯片廠商有機會縮小軟件生態的差距。一種樂觀設想是,如果AI代碼生成工具能針對國產AI芯片自動優化算子,適配門檻將大幅降低。上述資深算法工程師解釋,如果國產AI廠商能提供詳盡的芯片架構文檔和豐富的代碼案例,爲代碼生成工具提供充足的背景信息,開發者未來或許可以藉助AI讓算子在不同芯片之間遷移,大幅減少開發工作量。屆時,CUDA的軟件生態壁壘可能會進一步削弱。一位華爲技術人士的看法是,“CANN+MindSpore”目前和“CUDA+PyTorch/TensorFlow”相比,的確歷史積澱不足。但昇騰是開放的,CANN支持客戶通過PyTorch/TensorFlow等主流框架使用昇騰。華爲的MindSpore也在不斷提升易用性,貼近開發者習慣。在他看來,國產AI芯片想提升競爭力,必須形成生態規模。爲此,應該扶持主流的國產技術路線。華爲目前在採取務實的策略。一方面,持續打磨自家的MindSpore框架;另一方面,讓 CANN兼容PyTorch/TensorFlow等主流框架,吸引開發者將大模型無縫遷移到昇騰硬件上,同時完善自己的軟件生態。目前,昇騰支持開發者將在其他芯片上訓練的大模型一鍵部署到昇騰上。通過“非對稱”競爭,贏得戰略窗口
昇騰持續進步的同時,美國政府的芯片出口管制始終是中國AI產業頭上的“達摩克利斯之劍”。這些威脅還在步步緊逼。中美AI產業的戰略博弈中,有一條主線——美國政府一直希望限制中國獲取先進AI芯片,鎖死中國的AI技術上限。具體管制手段包括不限於:其一,禁止中國大陸採購最先進的AI芯片。美國商務部工業安全侷限定了英偉達對中國市場出售AI芯片的性能上限,今年4月又限制英偉達對華出售“特供”的H20芯片。其二,禁止荷蘭ASML公司對華出售EUV(極紫外光刻)光刻機。中國半導體制造工藝暫時被限制在7納米及以上水平,中國目前很難獲得臺積電16納米以下數據中心AI芯片的代工。其核心目的是,讓中國國產的AI芯片始終和美國存在工藝製程的代際差。然而,讓國產AI芯片從能用變得好用,已經是中國產業界的共識。一位芯片技術人士今年4月末曾對《財經》表示,從拜登政府到特朗普政府,美國每一輪出口管制都在倒逼中國提升AI芯片的自研意志和自研能力。如何讓國產AI芯片從能用變得好用?系統工程和工藝製程,是兩個重要方向。哪怕是英偉達,也是在兩條腿走路。對中國的有利之處是,近兩年,半導體工藝提升帶來的邊際效應在衰減。隨着晶體管尺寸逼近物理極限,提升工藝的難度、成本急劇增加,功耗、散熱的挑戰也在急劇提升。以英偉達B200爲例,它採用3納米工藝,相比4納米的H100,單顆GPU性能提升30%,功耗增加超過70%。英偉達的這一代產品在系統工程方向進行了大幅改進——英偉達的GB200 NVL72,就是把72枚GB200集成在一個機櫃,做成一個超節點。從英偉達的產品演進來看,系統工程帶來的性能提升,比改進芯片工藝製程更簡單直接。一位華爲技術專家的看法是,短期內系統工程帶來的提升的確更有效,這也是當前形勢下華爲優先努力的方向。上述華爲技術專家認爲,從單芯片提升路徑來看,從7納米到5納米、3納米、2納米,每代芯片工藝帶來的性能提升有限,而且成本極高。系統工程優化,帶來的算力效率提升,約等於兩代到三代的芯片工藝演進。這一定程度彌補了芯片工藝不足。AI芯片的半導體工藝正朝着2納米方向前進,大模型訓練也正在朝着十萬卡集羣的方向前進。有兩個核心問題,近2年-3年一直困擾着中國AI產業——如何用國產AI芯片訓練出能夠媲美國際科技巨頭的大模型?如何讓國產AI芯片持續迭代,跟上芯片工藝製程的演進。隨着美國政府的出口管制步步緊逼,這兩個命題正變得越來越急迫。但是,盤古Ultra、盤古Ultra MoE這兩款大模型,以及CloudMatrix 384“超節點”的出現意味着,國產算力也能訓練出世界一流的大模型。國產算力在重重限制下,也能另闢蹊徑並持續演進。昇騰縮小差距的種種系統工程方案,是一種典型的“非對稱”競爭。它是特定歷史時期和特定限制條件下的有效策略。這爲中國未來在可見時間內,突破國產光刻機和更先進工藝製程的國產AI芯片,爭取了寶貴的戰略窗口。責編 | 張生婷
題圖 | 視覺中國

Scroll to Top