

剛剛,Google DeepMind 推出一款新型 DNA 序列模型——AlphaGenome,該模型可以助力調控變異-效應的預測,有望爲基因組功能研究提供新視角,目前已經可以通過 API 獲取。
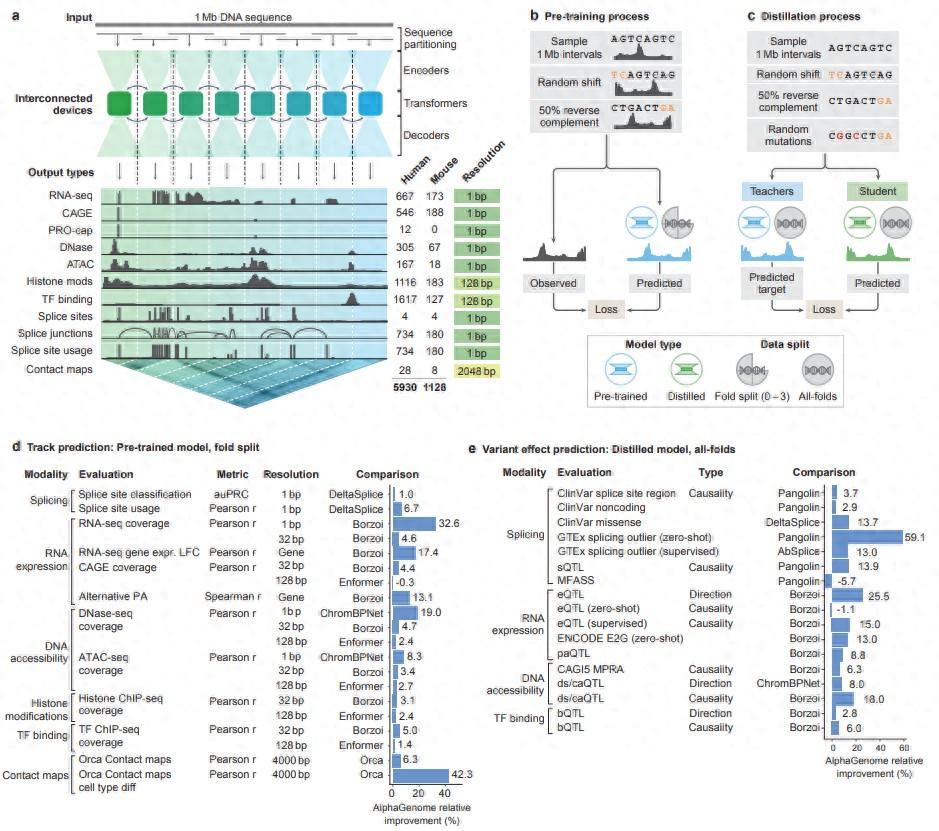
圖 | AlphaGenome 的架構(來源:https://storage.googleapis.com/deepmind-media/papers/alphagenome.pdf)
相關論文的共同一作包含一位名爲 Jun Cheng 的華人作者。他目前在 Google DeepMind 擔任研究人員。資料顯示,其博士畢業於德國慕尼黑工業大學。

圖 | Jun Cheng(來源:https://chengjun.me/)
據介紹,AlphaGenome 能夠更全面、更準確地預測人類 DNA 序列中的單個變異或突變如何影響了一系列調控基因的生物過程,並能輸出高分辨率預測結果。
DeepMind 研究副總裁普什米特·科利(Pushmeet Kohli)表示:“我們首次創建了一個單一模型,將理解基因組所面臨的許多不同挑戰統一起來。”不過,他也表示:“AlphaGenome 可能不會完整地模擬整個細胞……但它開始在某種程度上揭示 DNA 更廣泛的語義。”
據瞭解,AlphaGenome 試圖探索有關改變 DNA 字母如何改變基因活性的背後機制,以及試圖回答最終基因突變如何影響人類健康這一基本問題,以便進一步地簡化生物學家的工作。美國紀念斯隆凱特琳癌症中心的計算生物學家迦勒·拉羅(Caleb Lareau)提前接觸了 AlphaGenome,他說:“我們擁有構成人類基因組的 30 億個 DNA 字母,但每個人都略有不同,我們並不完全瞭解這些差異的作用。這是迄今爲止模擬這種情況最強大的工具。”拉羅表示,AlphaGenome 不會從根本上改變他的實驗室日常工作方式,但可能會允許進行新類型的研究。例如,有時醫生會遇到患有極罕見癌症、帶有不熟悉突變的患者。AlphaGenome 可以指出哪些突變纔是真正導致根本問題的原因,從而爲治療指明方向。
爲了推動學界研究,Google DeepMind 通過 AlphaGenome API 提供 AlphaGenome 預覽版,目前僅供非商業研究使用,並計劃在未來發布該模型。預計其將幫助研究人員更好地理解基因組功能、疾病生物學,並最終推動新的生物學發現和新療法的開發。需要注意的是,本次模型並未針對直接臨牀目的進行設計或驗證。

AlphaGenome:能分析多達 100 萬個 DNA 鹼基,並能以單個鹼基的分辨率進行預測
而與現有的 DNA 序列模型相比,AlphaGenome 具有幾個獨特的特點:
第一,其具備高分辨率的長序列上下文。該模型能夠分析多達 100 萬個 DNA 鹼基,並能以單個鹼基的分辨率進行預測。長序列上下文對於覆蓋遠距離調控基因的區域至關重要,而鹼基分辨率對於捕捉精細的生物學細節也至關重要。以往的模型不得不在序列長度和分辨率之間做出權衡,這限制了它們能夠聯合建模並準確預測的模態範圍。AlphaGenome 解決了這一侷限性,同時沒有顯著增加訓練資源,訓練單個 AlphaGenome 模型(不進行蒸餾)僅需四小時,且所需的計算預算僅爲訓練原始 Enformer 模型的一半。
第二,其具備綜合多模態預測能力。通過解鎖對長輸入序列的高分辨率預測,AlphaGenome 能夠預測最廣泛的模態範圍。在此過程中,AlphaGenome 能爲研究人員提供關於基因調控複雜步驟的更全面信息。
第三,其具備高效變體評分能力。除了能夠預測多種分子特性外,AlphaGenome 還能在一秒鐘內高效評估一個基因變異對所有這些特性的影響。它通過對比突變序列與未突變序列的預測結果,並針對不同模態採用不同方法高效總結這種對比來實現這一功能。
第四,其具備新型剪接位點建模能力。許多罕見的遺傳性疾病,如脊髓性肌萎縮症和某些類型的囊性纖維化,可能是由 RNA 剪接錯誤引起的。RNA 剪接是一個過程,在此過程中,RNA 分子的部分被移除或“剪掉”,剩餘的端部重新連接。AlphaGenome 首次能夠直接從序列中明確模擬這些連接點的位置和表達水平,從而能夠幫助人們更深入地瞭解遺傳變異對 RNA 剪接的影響。
基因組是我們細胞的指令手冊,它是一套完整的 DNA 序列,幾乎指導着生物體的每一個部分,從外觀和功能到生長和繁殖。基因組 DNA 序列中的微小變異可以改變生物體對環境的反應或對疾病的易感性。但是,在分子水平上解讀基因組的指令是如何被讀取的,以及當發生微小的 DNA 變異時會發生什麼,仍然是生物學最大的謎團之一。
德國慕尼黑工業大學計算醫學教授朱利安·加尼厄(Julien Gagneur)表示:“癌症的一個標誌是 DNA 中的特定突變會使錯誤的基因在錯誤的環境中表達。這種類型的工具在識別哪些突變會破壞正常基因表達方面非常重要。”同樣的方法也可以應用於患有罕見遺傳疾病的患者,其中許多人即使他們的 DNA 已經被解碼,也從未了解到他們病情的根源。“我們可以獲得他們的基因組,但我們不知道哪些基因改變會導致疾病。”加尼厄說表示。因此,他認爲AlphaGenome 可以爲醫學研究人員提供一種診斷此類病例的新方法。
據介紹,AlphaGenome 模型以長 DNA 序列(最多 100 萬個鹼基對)爲輸入,並能預測數千個表徵其調控活性的分子特性。該模型還能通過比較突變序列與未突變序列的預測結果,對基因變異或突變的影響進行評分。
預測屬性包括基因在不同細胞類型和組織中的起始位置和終止位置、剪接位置、產生的 RNA 量,以及哪些 DNA 鹼基是可接近的、彼此靠近的或被某些蛋白質結合的。訓練數據則來源於一些大型公共聯盟,包括 ENCODE、GTEx、4D Nucleome 和 FANTOM5,這些聯盟通過實驗測量了這些屬性,涵蓋了數百種人類和小鼠細胞類型和組織中基因調控的重要模式。
另據悉,AlphaGenome 架構利用卷積層來初步檢測基因組序列中的短模式,藉助 Transformer 在序列的所有位置之間傳遞信息,並通過最後的一系列層將檢測到的模式轉化爲針對不同模態的預測。在訓練過程中,針對單個序列的這種計算會分佈在多個相互連接的張量處理單元(TPU,Tensor Processing Units)上進行。
據瞭解,該模型基於 Google DeepMind 之前的基因組學模型 Enformer 構建,並與專門用於分類蛋白質編碼區域內變異影響的 AlphaMissense 相輔相成。蛋白質編碼區域佔基因組的 2%。其餘 98% 的區域稱爲非編碼區,對於協調基因活性至關重要,且包含許多與疾病相關的變異。而 AlphaGenome 爲解讀這些廣闊的序列及其內的變異提供了新的視角。
未來,AlphaGenome 將允許那些目前只能在實驗室中進行的某些類型實驗遷移到計算機上開展虛擬實驗。例如,假如一些熱心人士捐贈了 DNA,針對這些 DNA 進行研究往往會發現數千種遺傳差異,而每種差異都會略微增加或降低一個人患阿爾茨海默病等疾病的幾率,因此這類研究具有重要意義。
不過,不要指望 AlphaGenome 能對個人做出太多預測。它提供的是基因活性的具體分子細節的線索,而不是像美國 DNA 鑑定公司 23andMe 的產品那樣能夠揭示一個人的特徵或祖先。Google DeepMind 也在一份聲明中表示:“我們尚未爲個人基因組預測設計或驗證 AlphaGenome,這是 AI 模型已知的挑戰。”
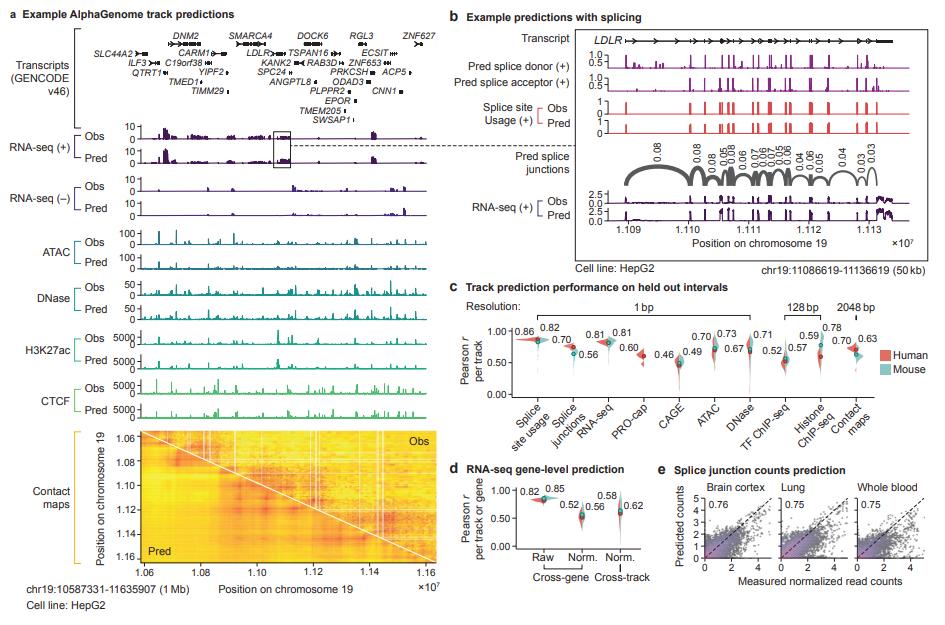
(來源:https://storage.googleapis.com/deepmind-media/papers/alphagenome.pdf)

在各項基準測試中均展現頂尖性能,已被用於研究癌症相關突變潛在機制
目前,AlphaGenome 已經在廣泛的基因組預測基準測試中取得了最先進的性能,例如預測 DNA 分子的哪些部分將緊密相鄰,預測基因變異是否會增加或減少基因的表達,或者預測它是否會改變基因的剪接模式。
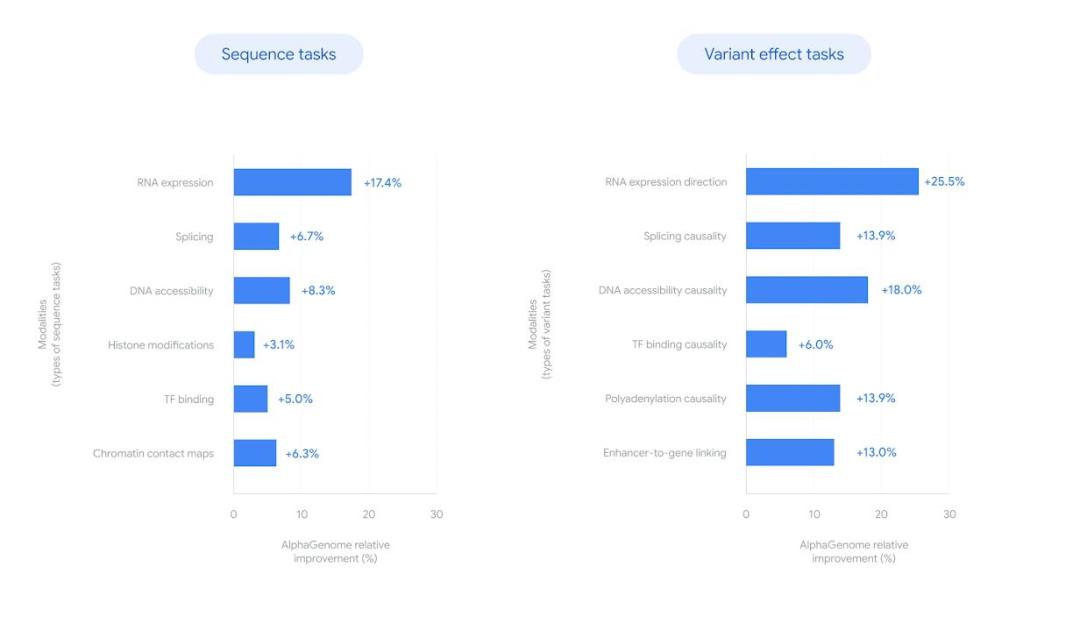
(來源:Google DeepMind)
在對單條 DNA 序列進行預測時,AlphaGenome 在 24 項評估中有 22 項表現優於最佳外部模型。而在預測變異的調控效應時,它在 26 項評估中有 24 項表現與最佳外部模型相當或更優。
據瞭解,此次比較包括專門用於各項任務的模型。而 AlphaGenome 是唯一能夠聯合預測所有評估模態的模型,這凸顯了其通用性。
AlphaGenome 的通用性使研究人員能夠通過一次 API 調用,同時探索一個變體對多種模態的影響。這意味着研究人員可以更快地生成和測試假設,而無需使用多個模型來研究不同的模態。
此外,AlphaGenome 的出色表現表明,它已在基因調控的背景下學習了相對通用的 DNA 序列表示方法。一旦該模型得到完全發佈,研究人員將能夠根據自己的數據集對其進行調整和微調,以更好地解決他們獨特的研究問題。
因此,這種方法提供了一個靈活且可擴展的架構。通過擴展訓練數據,AlphaGenome 的能力可以得到提升,從而取得更好的性能,覆蓋更多的物種,或納入額外的模態使模型變得更加全面。
而 AlphaGenomes 的預測能力,也將有助於多個研究方向的發展:
其一,用於疾病理解:通過更準確地預測基因突變,AlphaGenome 可幫助研究人員更精確地查明疾病的潛在原因,並更好地解釋與某些特徵相關的變異的功能影響,從而可能發現新的治療靶點。並且,該模型特別適合研究具有潛在重大影響的罕見變異,例如研究導致罕見孟德爾遺傳病的變異。
其二,用於合成生物學:其預測結果可用於指導設計具有特定調控功能的合成 DNA,例如設計僅在神經細胞中激活基因,而在肌肉細胞中不激活的 DNA。
其三,用於基礎研究:它可以通過協助繪製基因組關鍵功能元件圖譜並明確其作用,以及識別調節特定細胞類型功能的最基本 DNA 指令,來加速人們對基因組的理解。例如,Google DeepMind 團隊已經使用 AlphaGenome 來研究癌症相關突變的潛在機制。在一項針對 T 細胞急性淋巴細胞白血病(T-ALL,T-cell acute lymphoblastic leukemia)患者的現有研究中,研究人員觀察到基因組中特定位置的突變。利用 AlphaGenome,可以預測這些突變會通過引入 MYB DNA 結合基序來激活鄰近的 TAL1 基因,這不僅能複製已知的疾病機制,並凸顯了 AlphaGenome 將特定非編碼變異與疾病基因聯繫起來的能力。
雖然 AlphaGenome 能夠預測分子結果,但它無法全面揭示遺傳變異如何導致複雜性狀或疾病,因此這通常涉及更廣泛的生物過程比如發育和環境因素,而這超出了本次模型的直接應用範圍。目前,Google DeepMind 團隊並未將 AlphaGenome 設計或驗證用於個人基因組預測。相反,該團隊更側重於描述其在個體遺傳變異上的表現特徵。
總的來說,AlphaGenome 標誌着 DNA 研究向前邁出了重要一步,但同時也要認識到其目前的侷限性。與其他基於序列的模型一樣,其依然很難準確捕捉距離非常遠的調控元件的影響(比如距離超過 10 萬個 DNA 鹼基的調控元件)。因此,Google DeepMind 團隊的另一個重點是進一步提高模型捕捉細胞和組織特異性模式的能力。
參考資料:
https://www.technologyreview.com/2025/06/25/1119345/google-deepmind-alphagenome-ai/
https://storage.googleapis.com/deepmind-media/papers/alphagenome.pdf
https://chengjun.me/
運營/排版:何晨龍



