

近日,由三位美國麻省理工學院(MIT)華人博士爲主力完成的一項具身智能研究論文登上了 Nature 主刊。論文前三位作者分別是:李思哲、張安南和陳博遠。資料顯示,陳博遠已於 2025 年 6 月獲得博士學位,並已入職 OpenAI 擔任研究科學家(這可能也側面證實了 OpenAI 確實正在研發硬件產品)。

圖 | 從左到右:李思哲、張安南和陳博遠(來源:資料圖)

僅通過視覺就能控制機器人
對於這篇論文,李思哲在社交媒體上介紹稱:“我們的核心信息很簡單,即一個有能力的具身智能必須瞭解自己的身體在哪裏,並能充分利用自己的身體。”
在這項研究中,他們提出一種基於視覺的深度學習方法,該方法僅通過視覺就能實現對機器人的控制,只需利用一個 RGB 相機就能高精度地執行預定運動軌跡。
而他們之所以開展這項研究是因爲:傳統機器人可以輕易地建模爲由關節連接的剛性連桿。但是,仿生機器人往往柔軟或由多種材料製成,因此非常缺乏感知能力,而且其材料特性可能會在使用過程中發生變化,所以如何對其建模和控制仍是一項未解難題。
爲此,他們提出了上述這種利用深度神經網絡將機器人的視頻流映射到其視覺運動雅可比場的方法。
據介紹,本次方法僅通過單個攝像頭就能實現對機器人的控制,無需針對機器人的材料、驅動方式或傳感能力做出任何假設,並且只需通過觀察隨機指令的執行過程即可完成訓練,完全無需專家干預。
在不同的機器人操縱器上,他們針對本次方法進行了驗證,這些操縱器均由前人團隊打造,在驅動方式、材料、製造工藝和成本方面各不相同。
第一款操縱器是 UR5 機器人手臂,其於此前由丹麥 Universal Robots 公司開發。第二款操縱器是 Allegro Hand,其於此前由韓國 Wonik Robotics 公司開發。第三款操縱器是 Poppy 機器人手臂,其於此前由法國波爾多大學 Flowers AI & CogSci 實驗室開發。
在基於上述操縱器的實驗中:
首先,本次方法實現了平滑的軌跡控制,成功控制了安裝在 UR5 上的氣動手臂,讓其從玻璃杯中取出工具並能使用工具推動蘋果。

(來源:Nature)
其次,對於 Allegro Hand 本次方法能夠讓其握成一個拳頭。基於此前由美國西北大學團隊打造的手性剪切輔助材料(HSAs,Handed Shearing Auxetics)平臺上,Allegro Hand 能夠執行各種伸展指令和旋轉指令。

(來源:Nature)
再次,對於 Poppy 機器人手臂,本次方法讓其描繪出 MIT 這三個字母。
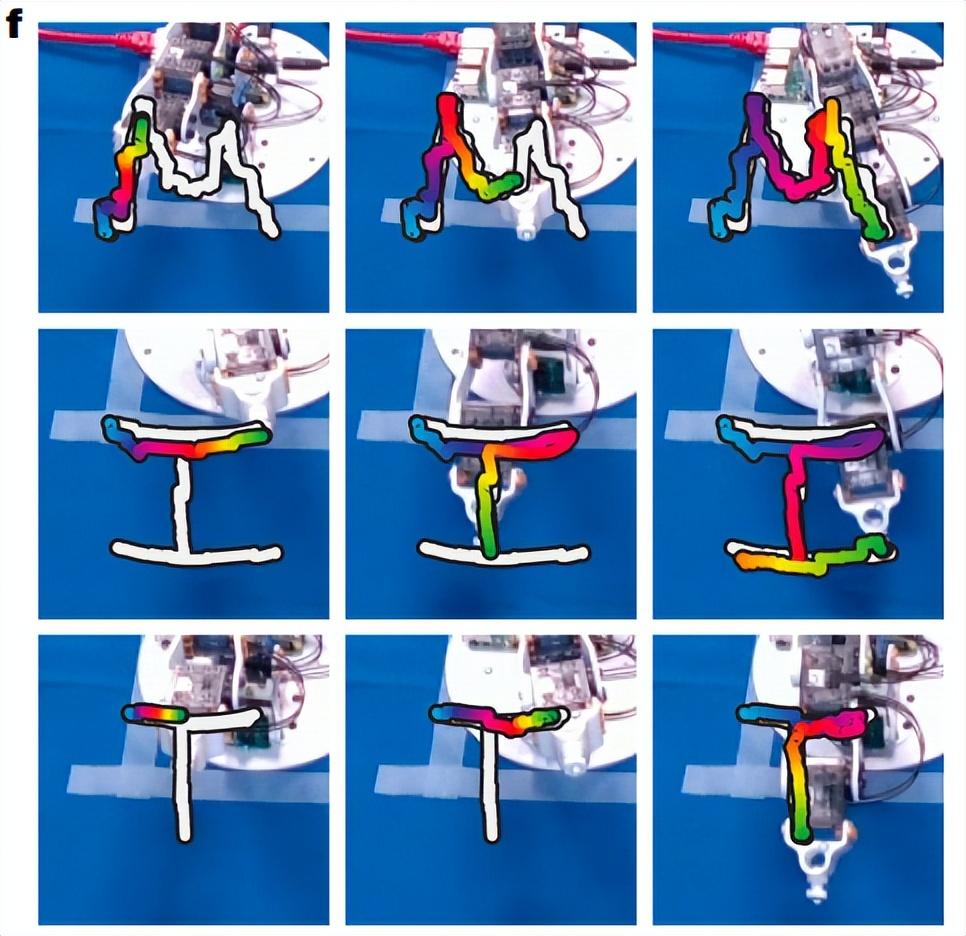
(來源:Nature)
總而言之,在一系列不同的機器人上,本次系統無需任何專家建模或定製,就能控制這些系統執行各種長期技能。這意味着該方法實現了精確的閉環控制,並還原了每個機器人的因果動態結構。
由於本次方法僅使用普通攝像頭作爲唯一傳感器就能實現機器人控制,因此研究團隊預計這項研究將拓寬機器人系統的設計空間,並能爲降低機器人的自動化門檻奠定基礎。

視覺運動雅可比場
據介紹,本次方法的框架由兩個關鍵部分組成:
首先,是一個基於深度學習的狀態估計模型,該模型僅從單一流式視頻中即可推斷出機器人的三維表徵,這種表徵既編碼了機器人的三維幾何結構,也編碼了其微分運動學特性——即三維空間中的任意一點在任意可能的機器人指令下將如何運動;
其次,是一個逆動力學控制器,該控制器在二維圖像空間或三維空間中對期望運動進行密集參數化,並能以交互速度生成機器人指令。
研究團隊發現,將演示軌跡參數化爲密集的點運動,是控制各種機器人系統的關鍵,這是因爲可變形機器人和靈巧機器人的運動無法通過單一三維座標系上指定的剛性變換得到良好約束。同時,他們的參數化方法使得各種系統能夠模仿基於視頻的演示。
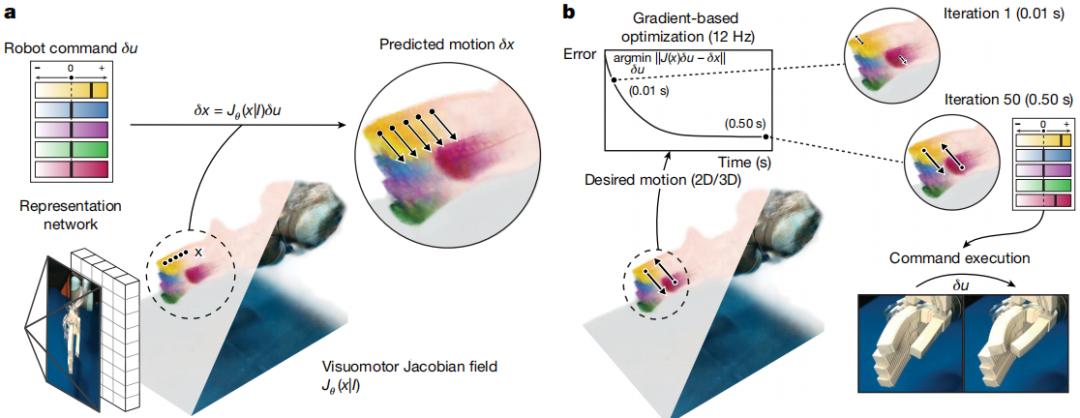
圖 | 此次使用的系統(來源:Nature)
狀態估計模型是一種深度學習架構,它能將機器人的單張圖像映射到三維神經場景表徵。該三維表徵可將任意的空間座標,映射到對應位置的機器人幾何特徵與機器人運動學特徵。
研究中,研究團隊重建了一個神經輻射場和一個創新的視覺-運動雅可比場。神經輻射場編碼了機器人在每個三維座標處的三維形狀和外觀,而視覺-運動雅可比場則將三維中的每個點映射到一個線性算子,該算子將該點的三維運動表示爲機器人執行器命令的函數。神經輻射場將三維座標映射到其密度和輻射度,以此作爲機器人幾何結構的一種表徵。
爲了重建視覺運動雅可比場和輻射場,研究團隊使用了一個神經單視圖轉三維模塊。通過直接從攝像機觀測中重建機器人的幾何結構和運動學特性,使得狀態估計模型無需依賴機器人內置的傳感器。
據介紹,本次系統並非由人類專家針對電機、傳感器讀數與機器人的三維幾何結構及運動學特性之間的關係進行建模,而是直接從數據中學習並回歸這種關係。
與此同時,研究團隊所使用的狀態估計模型採用自監督方式訓練,訓練數據來自 12 臺 RGB-D 攝像機拍攝的視頻流,這些攝像機從不同視角記錄了機器人執行隨機指令的過程。對於每個攝像頭流,他們使用光流法和點跟蹤方法提取了二維運動。
在每個訓練步驟中,他們會從 12 臺攝像機中選擇一臺,將其作爲重建方法的輸入。從這張單一的輸入圖像中,他們重建出了視覺運動雅可比場和輻射場,從而能對機器人的三維幾何結構和外觀進行編碼。只需給定一個機器人指令,即可使用雅可比場來預測由此產生的三維運動場。
另據悉,研究團隊通過採用體繪製技術,將三維運動場渲染到其餘 12 臺攝像機中某一臺的二維光流上,並將其與觀測到的光流進行比較。這一過程訓練了雅可比場,使其能夠準確預測機器人的運動。

在閉環控制中仍然擁有高性能
評估本次方法在閉環控制中的性能,是必不可少的一個環節。其中,對於 Allegro Hand,研究團隊爲控制器預設了一條二維軌跡,該軌跡能夠追蹤相關的姿態。
軌跡完成後,他們利用內置的高精度關節傳感器和手部精確的三維正向運動學模型對誤差進行了量化。這時,只需依靠視覺系統就能控制 Allegro Hand 完成每根手指的完全屈伸,每個關節的誤差小於 3 度,每個指尖的誤差小於 4 毫米。
研究團隊還在 HSA 平臺上進行了驗證,結果表明本次系統無需重新訓練,就能在動態特性發生顯著變化的情況下成功控制機器人。他們還有意地針對 HSA 平臺進行了干擾:將總質量爲 350 克的校準重物固定在一根木棒上,並將木棒粘在 HSA 平臺的頂部。利用重物在平臺頂部施加了一個垂直力和一個扭矩,這使得平臺在靜止狀態下出現了明顯的傾斜。此外,木棒和重物還構成了視覺干擾。這時,研究團隊使用測量誤差小於 0.2 毫米的 OptiTrack 運動捕捉系統,並在 HSA 平臺表面粘貼了標記點,以便能夠量化目標姿態跟蹤中的位置誤差。結果發現,基於視覺的框架能夠控制機器人完成複雜的旋轉運動並達到目標配置,誤差僅爲 7.303 毫米,有效克服了系統動力學上的外部擾動。
對於三維打印的 Poppy 機械臂,研究團隊設計了目標軌跡,要求機器人在空中繪製一個正方形以及字母“MIT”。這些運動序列不在分佈範圍內,也未包含在研究團隊的訓練數據中。實驗中,他們在機械臂的末端執行器上安裝了 OptiTrack 標記點,以便測量三維位置誤差。在目標位姿跟蹤任務中,本次系統的平均誤差小於 6 毫米。
研究團隊還評估了其所使用的模型在實現不同視角間演示遷移上的能力。具體來說,其將模型通過將每個二維視頻幀提升到三維粒子狀態,將視頻轉換爲三維軌跡,從而實現了這一目標。從定量角度來看,本次方法取得了 2.2° 的較低中位誤差。
總的來說,本次方法能對三維打印的柔性系統進行建模和控制,全程無需任何人工建模,即便這些系統的動力學特性發生顯著變化也能適用。這一系統取代了原本需要長達一個月的人類專家建模流程,而且即便人類專家建模耗時如此之長,也無法應對材料、動力學特性或製造公差的變化。因此,研究團隊預計本次方法將有助於仿生型軟硬混合機器人的部署,並有望降低機器人自動化技術的入門門檻。
參考資料:
https://www.linkedin.com/in/lester-sizhe-li/
https://www.linkedin.com/in/annan-zhang/
https://www.linkedin.com/in/boyuan99/
Li, S.L., Zhang, A., Chen, B. et al. Controlling diverse robots by inferring Jacobian fields with deep networks. Nature 643, 89–95 (2025). https://doi.org/10.1038/s41586-025-09170-0
運營/排版:何晨龍



